Oracle Explain Plan
프로젝트를 진행하면서 다양한 문제에 경험하게 되고 그 문제를 해결하는 일을 반복하는데 그 중 하나가 Oracle 성능 문제다. 개발을 하면서 많이 만들었던 기능 중 하나가 통계였다. 각종 데이터들의 통계를 결과를 갖는 SQL문을 작성하다 보면 비교적 많은 Table을 Join 관계를 갖도록 하고 복잡한 조건문을 더하면서 비대해진 SQL문이 만들어지곤 한다. 적절하지 못한 Table Join 혹은 조건문 등으로 Table Full Search가 발생하는 경우가 있다. Oracle이 Data를 Select하는 과정에서 Full Search가 생기면 당연 과다한 시간(비용)이 발생하고 성능 저하의 원인이 되므로 SQL문장에서 Full Search가 발생되는 부분을 배제하는 것이 현명하다. 문제는 이러한 Full Search 발생을 어떻게 인지하냐는 것이다. 실제로 프로젝트에서 작성된 SQL문을 최초로 실행할 때 사람이 성능저하를 감지할 정도의 시간이 소요되어야 이러한 문제점을 인지하면서 작업을 진행하기도 했다. 그렇다고 소요시간이 극단적으로 짧게 데이터를 불러온다고 해서 효율적인 SQL문이라고 판단하기에도 무리가 있다. 시간이 지나서 DB에 Test할 때보다 훨씬 많은 데이터가 쌓이고 난 후에 전혀 다른 결과를 가져올 수도 있다. 따라서 성능을 판단할 수 있는 보다 더 객관적인 지표가 필요하다. 왜 성능이 좋지 않은 지를 판단하기 위해서는 작성한 쿼리에 대한 Optimizer가 생성한 실행 계획을 해석해야만 보다 더 정확한 원인을 파악할 수 있다. 개발자로써 DBA의 고도의 역량을 발휘하는 것까지는 아니라도 SQL Plan이 낯설게 느껴져선 안 된다는 판단을 하게 된다. 따라서 Oracle의 비용기반 최적화 기술 CBO의 기본 흐름과 Oracle에서 제공하는 Tool 인 DBMS_XPLAN을 통한 실행계획예측을 확인하는 사용법을 알아보도록 하겠다.
CBO란?
CBO(Cost Based Optimization)는 Oracle에 탑재된 비용기반 최적화 기술로써 지난 30년간 끊임없는 진화를 거쳐서 발전해 왔다. CBO 기술은 주어진 질의에 대해 각각의 실행계획에 대해 “시스템 통계치 -> Cardinality 예측 -> 비용 예측”의 단계를 거쳐 최소의 비용이 예상되는 실행 계획을 선택하는 기술이다.
CBO의 기본 흐름은 다음과 같다.
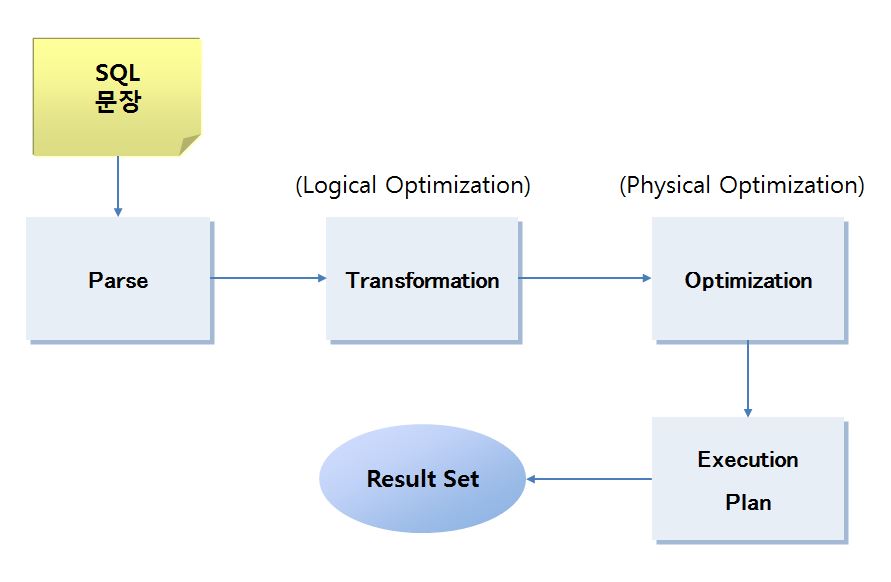
- Parse 단계 - Syntax를 체크하고 Object 이름과 권한 등을 확인
- Transformation 단계 – Subquery, Inline View 등의 복잡한 부분들을 해석하고 Predicate를 변환한다. Star Transformation 과 같은 복잡한 Transformation 도 이 단계에서 이루어진다. (CBO가 Version Up 되면서 가장 크게 개선되는 단계, SQL 문장을 구사하는 패턴이 점점 복잡해지고 새로운 유형의 Operation이 추가되면서 Transformation 단계의 역할의 비중이 커짐)
- Optimization 단계 – System Statistics 와 Object Statistics를 이용해 Optimization에 필요한 기본 정보를 얻고 Access Type 과 Join Type 을 고려한 비용 계산이 이루어진다. Query 의 조건을 만족하는 가장 최소의 비용을 갖는 실행 계획을 도출한다.
- 도출된 Execution Plan을 통해 Query를 실행하고 그 결과를 사용자에게 Return 한다.
사용자가 SQL 문장을 접수하면 Oracle은 기본적인 Parsing 작업을 수행한다. Syntax를 체크하고 Object 이름과 권한 등을 확인한다.
CBO Tools - DBMS_XPLAN
Oracle이 기본적으로 제공하는 Tool로서 기본 목적은 실행 계획의 예측을 보여주는 것이다. 사용법은 다음과 같다.
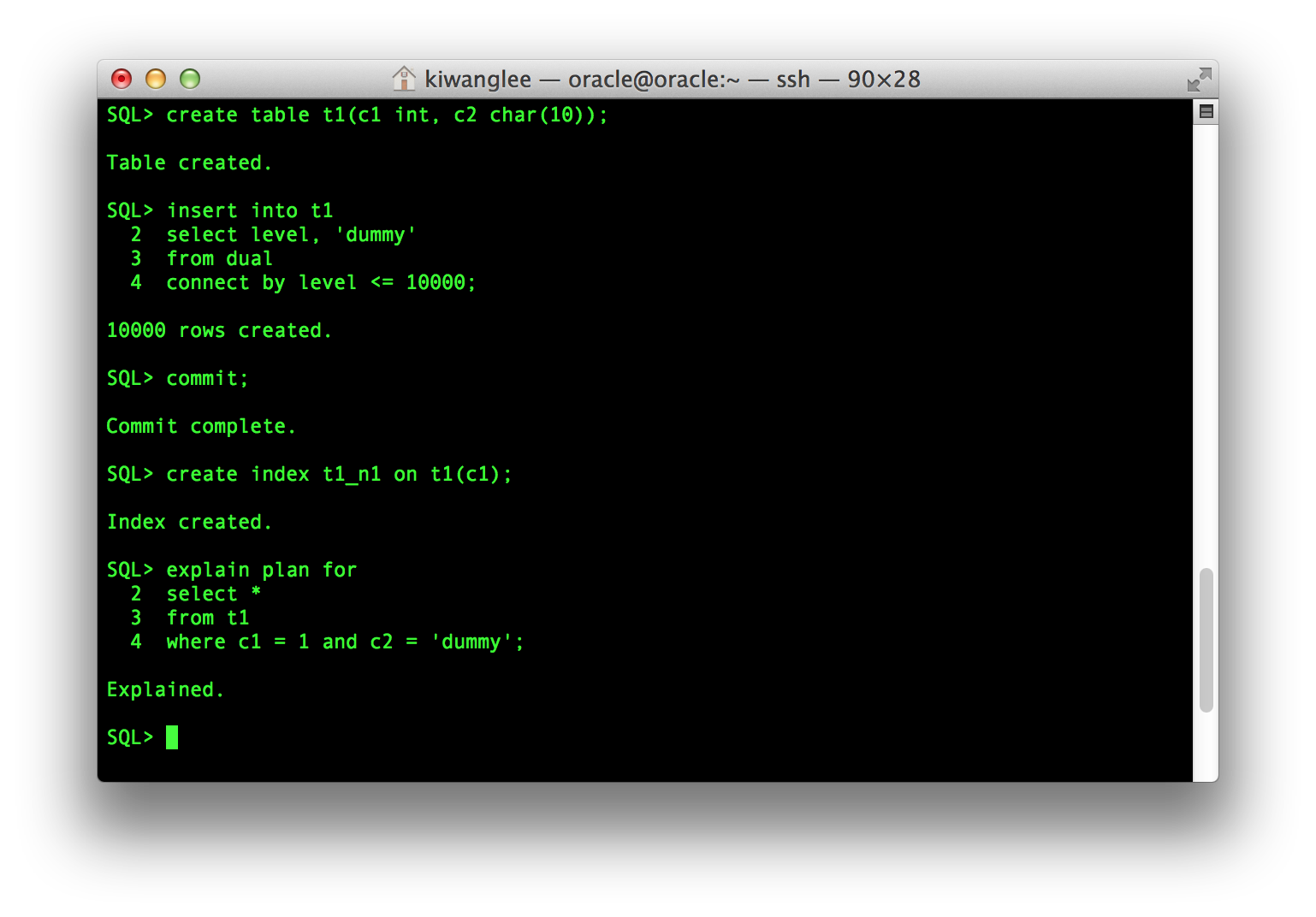
두개의 Column(c1, c2)을 가진 Table을 만들고 Column c1 에 대해서 Index를 생성한다.
EXPLAIN PLAN 명령을 통해 실행 쿼리를 저장하고, DBMS_XPLAN.DISPLAY 호출로 실행 계획을 볼 수 있다.
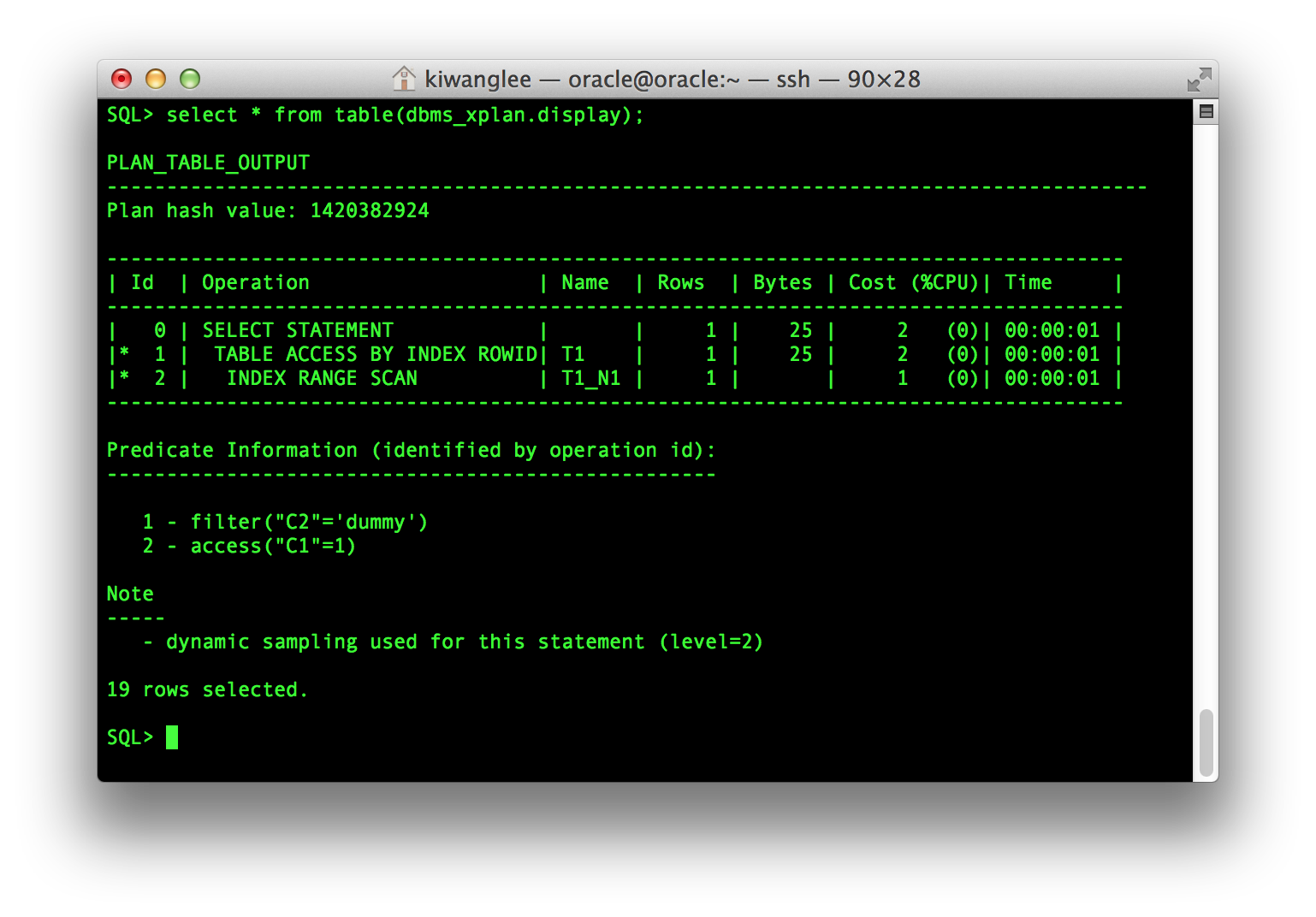
DBMS_XPLAN.DISPLAY Function 이 제공하는 값들은 다음과 같다
- Row Source Operation. 위의 예에서 Index t1_n1 을 INDEX RANGE SCAN으로 Access 하는 실행 계획이 수립될 것임을 보여준다
- Predicate Information Index t1_n1 에 대한 Range Scan 단계에서는 access(“C1”=1) Predicate가 사용되었다. Index Access 를 통해서 걸러진 Data는 1번 단계, 즉 TABLE ACCESS BY INDEX ROWID Operation 에서 filter(“C2”=’dummy’) Predicate를 이용해 다시 Filtering 된다.
- Note 정보를 통해 부가적으로 필요한 정보를 제공한다. 이 예제에서는 Dynamic Sampling이 사용되었음을 알려 준다. Oracle 10g 에서는 통계 정보가 없는 Table에 대해서 Dynamic Sampling을 수행한다.
위 예제에서 Predicate Information에 나오는 Access Predicate 와 Filter Predicate을 알아보자.
Access Predicate - Access Type을 결정하는데 사용되는 Predicate를 의미한다. 실제 Block을 읽기 전에 어떤 방법으로 Block을 읽을 것인가를 결정한다는 의미이다.
Filter Predicate - 실제 Block을 읽은 후 Data를 걸러 내기 위해 사용되는 Predicate(조건)를 의미한다.
Access Predicate 와 Filter Predicate 가 표현되는 방식에 대한 정확한 이해는 실행 계획 해석에 있어 필수적인 지식이다. 다음 예제는 Access Predicate와 Filter Predicate가 두가지 Join 동작 방식(Nested Loops Join과 Hash Join) 에 따라 어떤 표현방식의 차이가 있는지 보여준다.
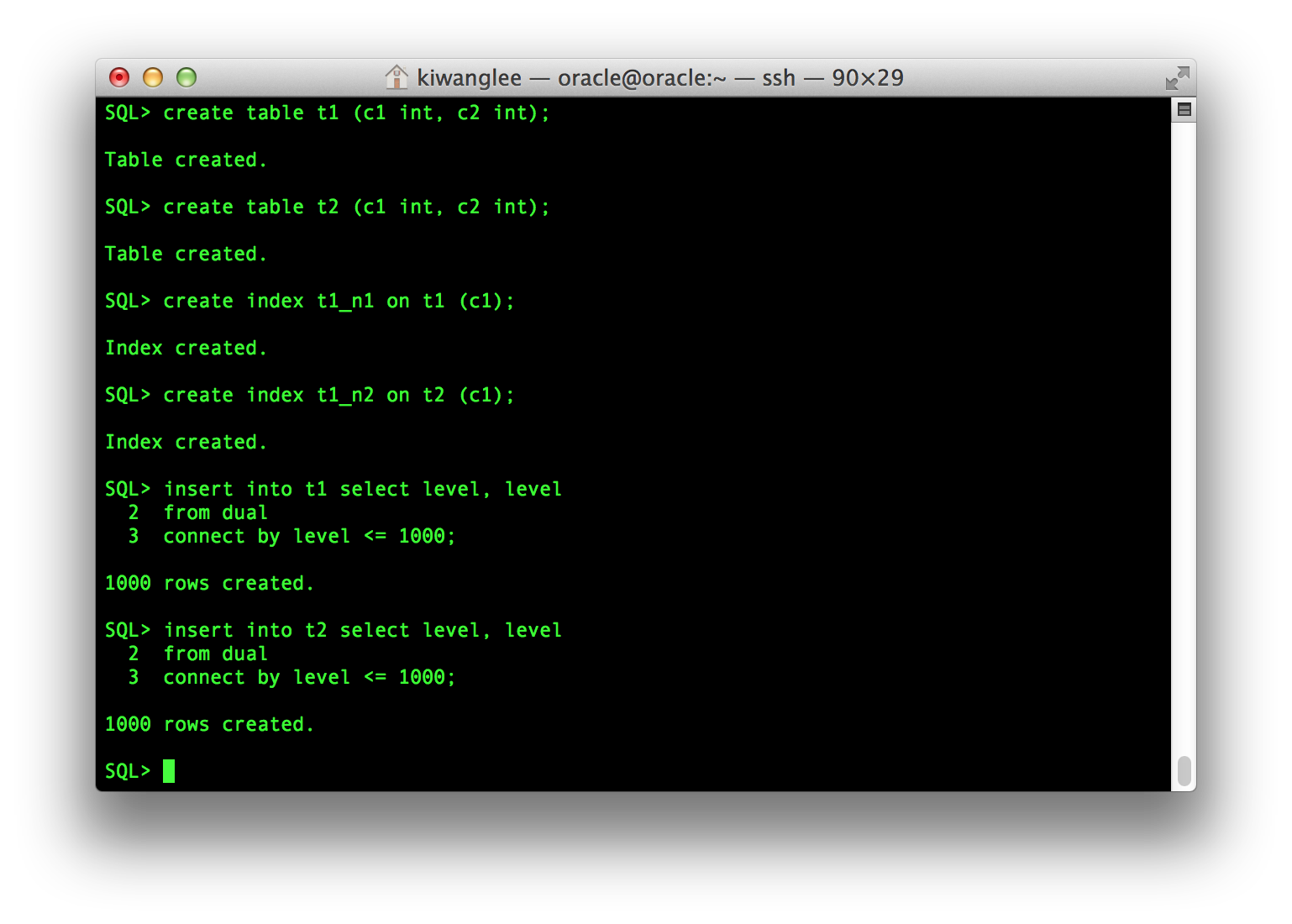
두 Table과(t1, t2) 두 Index(t1_n1, t1_n2)를 생성하고 데이터는 앞선 예제와 동일하게 각각의 Table에 Insert한다.
Nested Loops Join 방식의 DBMS_XPLAN.DISPLAY Function 이 제공하는 값을 살펴보면, Nested Loops Join 에서는 후행 Table 에 대한 Access 단계(4번)에서 Access Predicate 가 표현되는 것을 알 수 있다. Join 단계인 2번이 아니라 4번 단계에서 Access Predicate 정보가 출력되는 것에 주의해야 한다. Join에 참여하지 못하는 Column에 대한 조건(3번)은 Filter Predicate 로 표현된다.
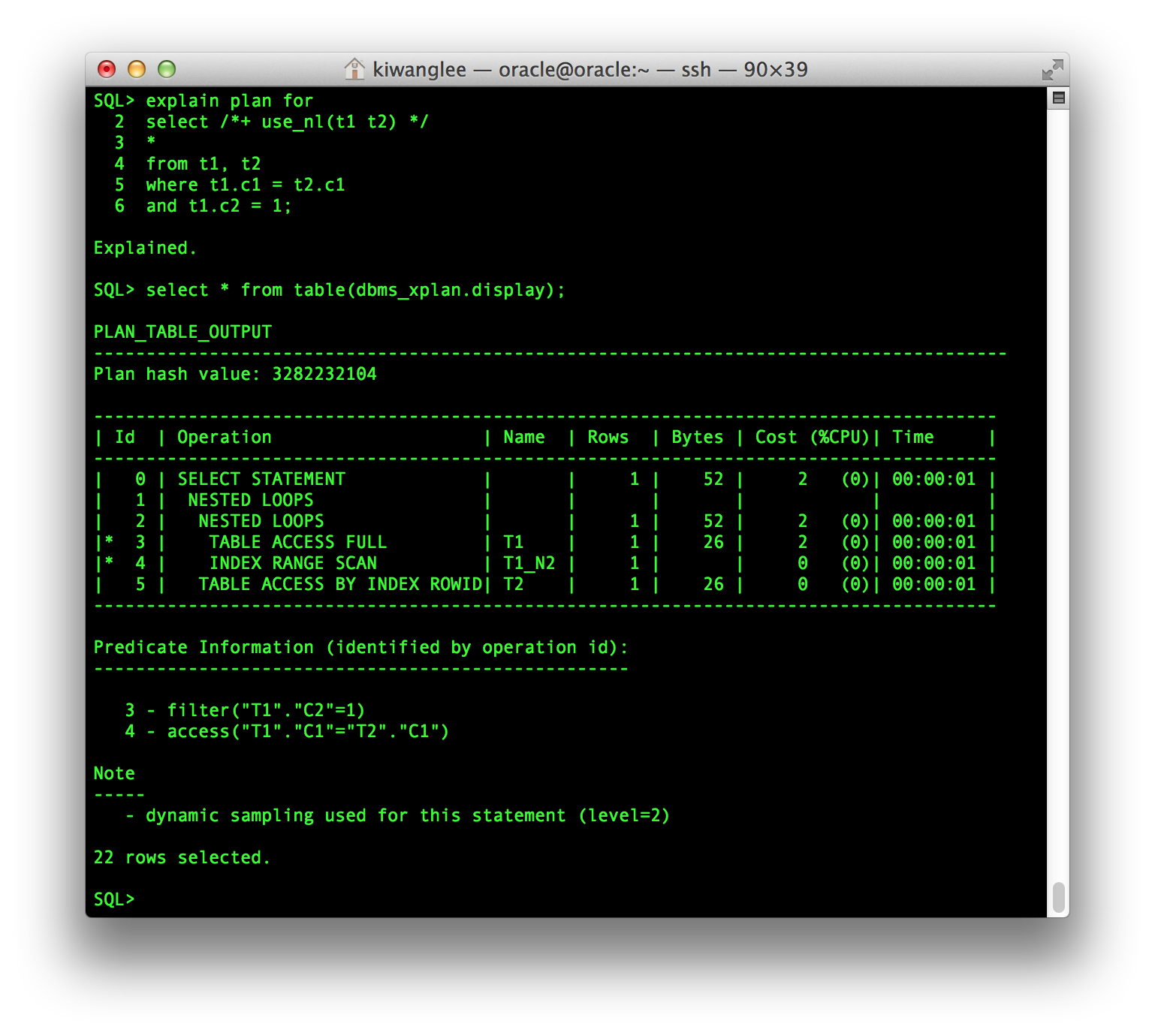
반면 Hash Join 에서는 Join 단계(1번)에서 Access Predicate 정보가 출력된다.
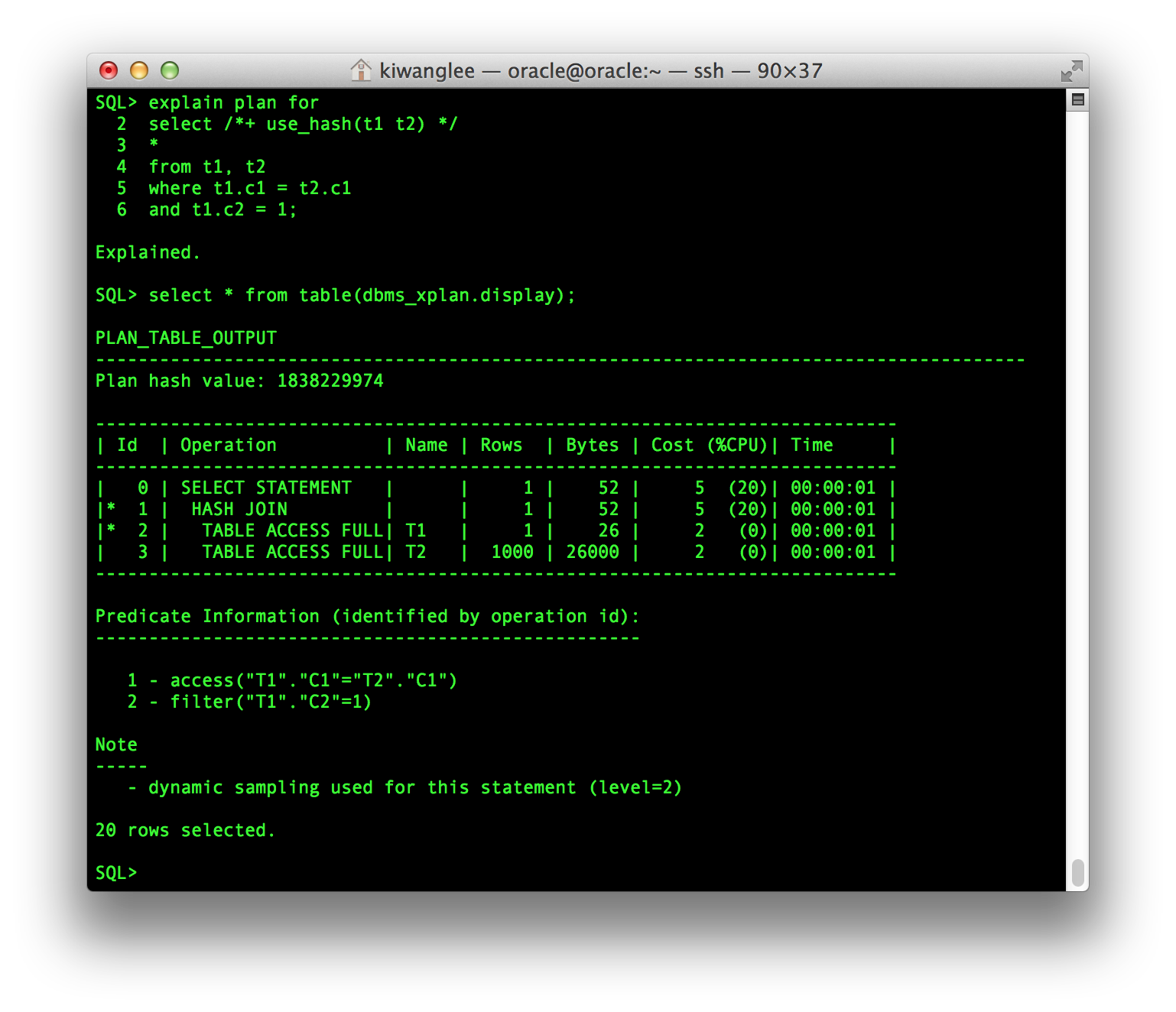
Nested Loops Join 과 Hash Join 두 Join의 동작 방식의 차이 때문에 Access Predicate 가 표현되는 방식의 차이가 발생한다. Nested Loops Join은 선행 Table 을 읽으면서 후행 Table을 한번씩 Access 하는 방식이다. 따라서 실제 Join은 후행 Table에 대한 Access 에서 발생한다. 따라서 후행 Table 을 읽는 단계가 Access Predicate가 된다. 반면에 Hash Join 은 선행 Table 을 먼저 Build 한 후, 후행 Table과 한번에 Join 하는 방식이다. 따라서 실제 Join이 발생하는 Hash Join 단계가 Access Predicate로 표현된다.
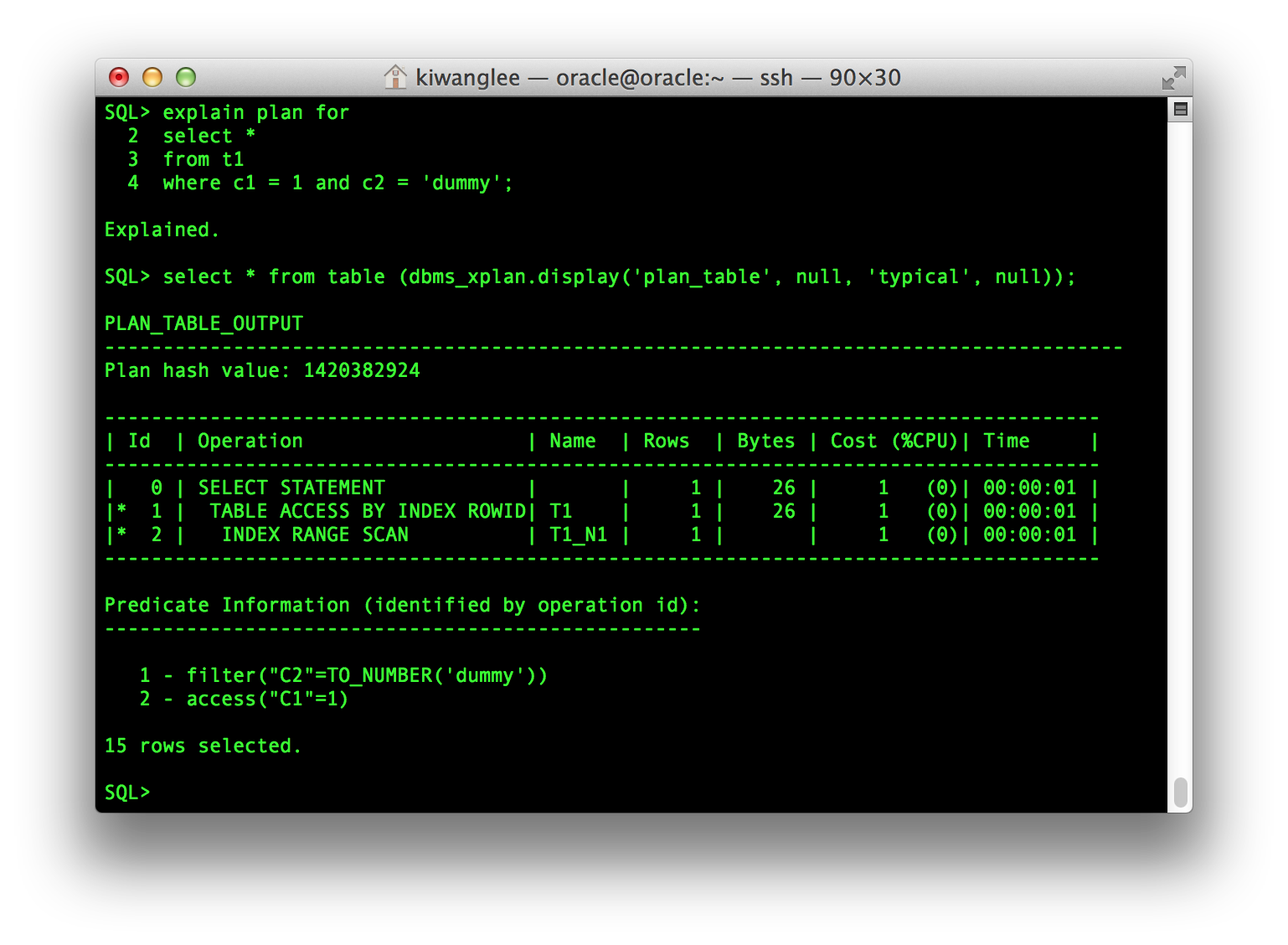
DBMS_XPLAN.DISPLAY Function 이 제공하는 Parameter 들을 잘 이용하면 더 많은 종류의 정보를 추출할 수 있다. 예를 들어 다음 2개의 문장은 동일한 결과를 Return한다.
select * from table(dbms_xplan.display);
select * from table (dbms_xplan.display('plan_table', null, 'typical', null);
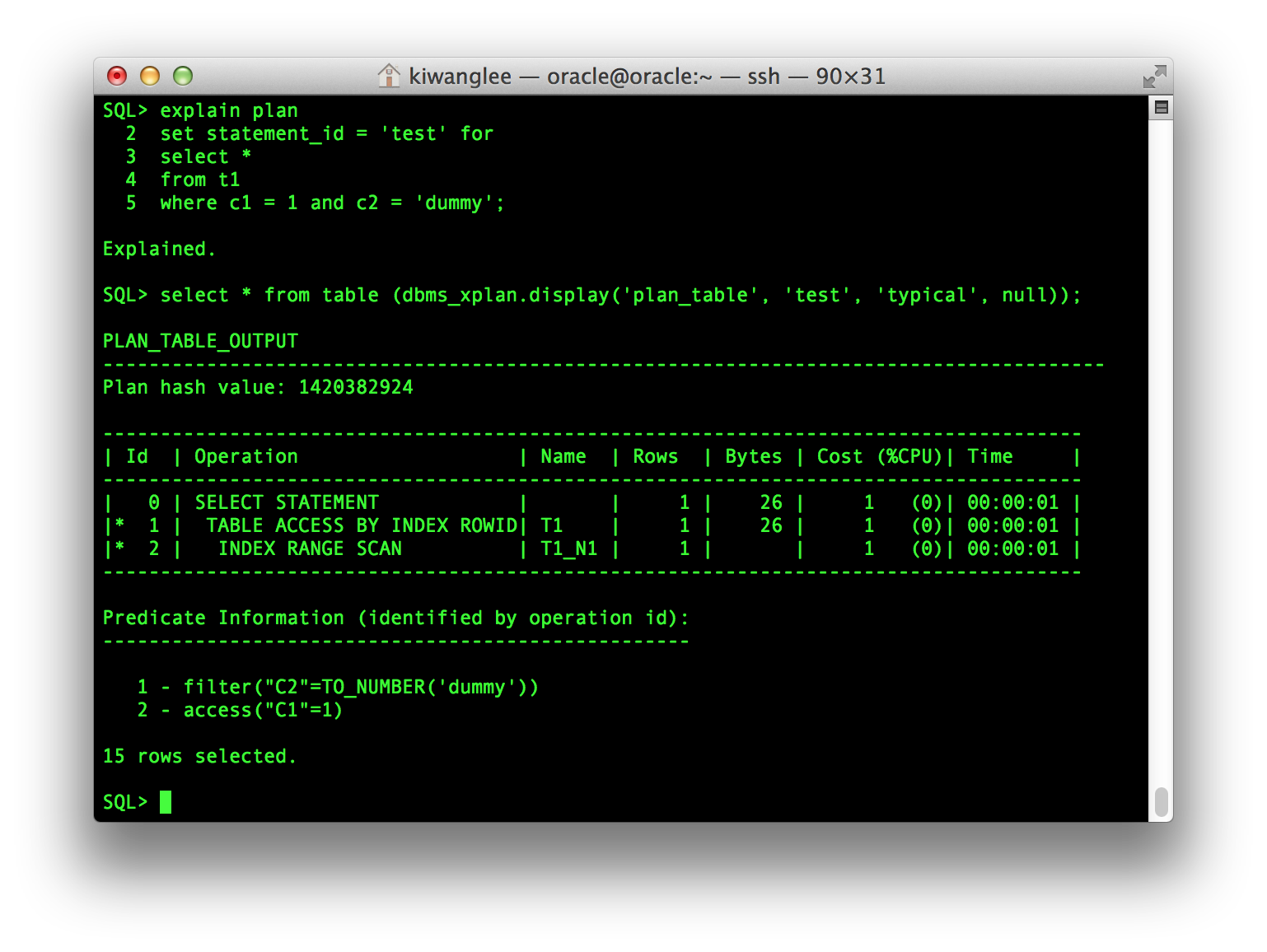
EXPLAIN PLAN 수행 시 Statement ID를 부여하여 다수의 쿼리를 각각 Statement ID에 따라 저장하고 Display 시 원하는 쿼리의 ID값을 지정해주면 된다. 아래 예제는 ‘test’라는 Statement ID를 지정한 예이다.
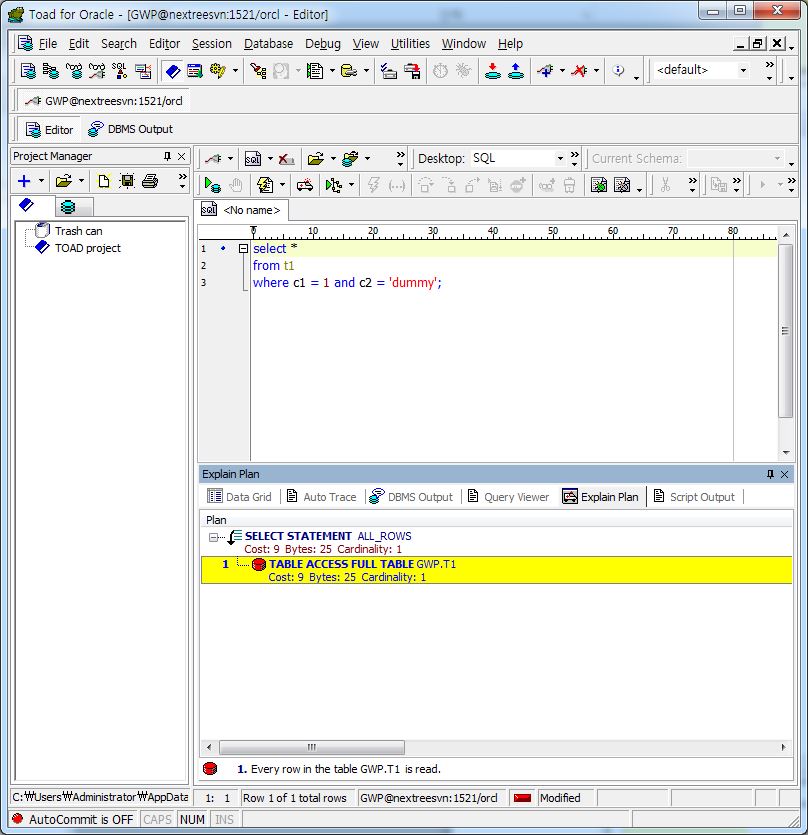
DBMS관리 Tool인 Toad를 이용하면 보다 쉽게 Explain Plan 정보를 확인할 수 있다. 사용법은 해당 쿼리를 지정하고 단축키 Ctrl + E 를 누른다.
DB Server 환경
CentOS 6.2
Oracle Database Express Edition 11g
SqlPlus
Client 환경
Mac OS X Mavericks
Windows 7
Toad for Oracle Xpert (ver. 10.5.0.41)
자료출처
Optimizing Oracle Optimizer

