Clustering이란 두대 이상의 서버가 하나의 서버가 처리하는 것처럼 보이도록 서버들 간의 확립된 연결(Establishing Connectivity) 입니다. 이 클러스터링은 장애 대응 시스템(fail-over), 부하분산(load balance) 시스템 혹은 병렬처리 프로세싱에 사용될 수 있는 기술입니다.
한 예로, 장애 대응 시스템의 클러스터링은 응용프로그램과 서비스의 고가용성(High-Availability)을 유지하기 위해 동시 작동하는 서버들의 집합입니다. 예를 들어 어떤 이유에서 하나의 노드에 장애가 생기면 다른 노드는 그 처리를 받고 사용자에게 무중단의 서비스를 제공합니다.
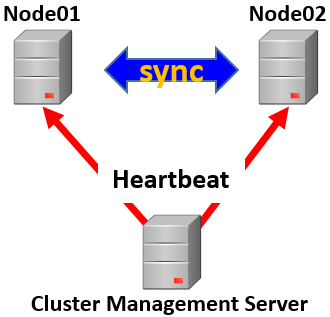
Clustering Diagram
클러스터 관리는 별도의 서버에서 수행되며 두 노드를 관리합니다. 이 관리서버는 주기적으로 두 노드에 상태 점검(Hearbeat)하여 하나의 노드에 장애가 발생시 다른 노드로 부하를 이전하는(Fail-Over) 역할을 수행합니다.
클러스터를 사용하려면 <업계에서 사용하는 클러스터링의 종류, 장단점을 알아야 합니다.
클러스터링의 장점
- 클러스터링은 확장가능한 솔루션입니다. 이는 나중에도 자원을 추가할 수 있습니다.
- 또한 Fail-over의 기본 속성이 있어 서버 작업 시 무중단으로 작업이 가능합니다.
클러스터링의 단점
- 비용이 매우 높습니다. 하드웨어의 고 사양과 평범하지 않는 설계는 더 많은 비용이 요구되지만 비용대비 효과는 더 크게 작용합니다.
- 더 많은 서버는 모니터링과 유지보수의 어려움으로 더 많은 비용이 발생합니다.
노드간 데이터 동기화 등의 이유로 노드의 처리량도 non-clustering 보다 더 많은 부하가 발생합니다.
근래 컨설팅 중 HA를 위해 시스템 이중화한 사례를 소개할까 합니다.
WEB, WAS, DB는 A(Active)/A 구조로 tire간 클러스터링 구조이며 서비스를 위한 Daemon은 A/P(Passive) 구조입니다. 이로 인해 L4는 A/P 구조이며 SVC의 Daemon을 감지하여 A/P 방식으로 트래픽을 제어합니다.
결과적으로 Active SVC1는 L4로 트래픽을 보내 재귀호출 하는 방식이 되어버립니다. 서버 자체적으로 해결할 수 있는 프로세싱이 불필요 트래픽과 부하가 발생하게 됩니다.
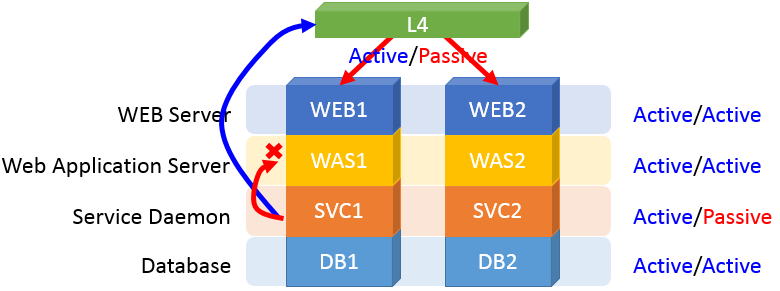
서비스 flow
이를 보완하기 위해 HA Cluster 구성을 위한 여러 솔루션 중 본 글에서는 요즘 OpenSource에 사용중인 “Pacemaker”를 다뤄보겠습니다.
Pacemaker는 Cluster 관리를 위해 근래 apache storm, openstack 등에 사용하는 분산 코디네이터 입니다.
Pacemaker 는 크게 5가지 기능이 있습니다.
- 응용프로그램 모니터링 및 제어기능 : 프로세스(리소트 에이전트:RA)를 모니터링 하고 제어합니다.
- 네트워크 모니터링 및 제어기능 : 클러스터 노드에 주기적으로 ping을 전송하여 연결 상태를 모니터링 합니다.
- 노드 모니터링 기능 : Heartbeat을 이용하여 노드를 모니터링하고 STONITH(Shoot The Other Node In The Head : Fencing Daemon) 기능은 통신 불가한 노드의 전원을 가제로 중지하여 split-brain(클러스터 내의 모든 노드들은 자신이 Primary 노드라고 인식하여 네트워크의 일시적 단절, 과반수 이상의 노드가 장애를 일으키는 현상)을 피합니다.
- 자기 감시 기능 : Pacemaker 관련 프로세스 감시합니다.
- 디스크 모니터링 및 제어기능 : 지정된 디스크 읽기를 정기적으로 실시, 액세스 상태를 모니터링 합니다.
그 외에 다양한 구성의 HA 클러스터에 대응합니다.
- 서비스 수준의 실패 시 노드와 서비스를 탐지하고 복구합니다.
- 공유 스토리지가 필요없이 스토리지에 종속되지 않습니다.
- 스크립트로 클러스터링 할 수 있다면 어떠한 서비스에도 종속되지 않습니다.
- 데이터 무결성을 보장하는 펜싱(STONITH)을 지원합니다.
- 대형, 소형 클러스터를 지원합니다.
- 중앙 컨트롤 형식의 quorate(quorum)과 계층구조의 resource-driven cluster 모두 지원합니다.
- 거의 대부분의 이중화 구성을 지원합니다.
- 자동으로 복제된 설정은 임의의 노드에서 업데이트 할수 있습니다.
- 동일지역이나 원격지에 걸처 광범위하게 클러스터를 구성할수 있습니다.
- 멀티 노드에서 활성화할 서비스에 대해 복제 기능 지원을 합니다.
- 서비스에 대한 멀티모드(master/slave, primary/secondary)를 지원합니다.
- 통합된 클러스터 관리 도구를 제공합니다.
보통 데이터 전환 방식과 노드 수에 따른 분류 두가지 방식이 쓰입니다.
데이터 전환 방식으로는 공유 구성, 비공유구성(PG-REX, twitter나 Instagram에서 사용하는 DRDB)와 노드 수에 따른 분류로는 1+1(Active/Standby구조), N+1(다수의Active노드와 하나의 Standby노드), N+M(다수의 Active노드와 다수의 Standby노드)로 분류합니다.
코어 컴포넌트는 다음과 포함합니다.
- Pacemaker : 핵심이며, 노드의 클러스터 집합에서 상호 관련 서비스를 시작, 복구를 조정하는 분산 상태를 유지합니다.
- Corosync : Corosync API는 노드 멤버에게 메시지(노드의 프로세스 상태)와 quorum을 제공합니다.
- libQB : 재사용을 통해 노드의 성능을 주목적으로 하는 라이브러리 입니다. 이는 고성능의 로깅, 트레이싱, ipc, 폴링을 제공합니다.
- Resource Agents : Pacemaker가 서비스를 관리할 수 있는 추상 개념입니다. 논리적으로 클러스터가 start, stop, 상태 점검을 위한 로직을 포함합니다.
- Fence Agents : Pacemaker가 장애상태인 노드를 분리할 수 있는 추상 개면입니다. 노드의 전원을 끄거나 네트워크 혹은 공유 스토리지의 엑세스를 막음으로 팬싱 기능을 수행합니다.
- OCF specification
내부 컴포넌트의 구성은 다음과 같습니다.
- CIB : Cluster Information Base
- CRMd : Cluster Resource Management daemon
- LRMd : Local Resource Management daemon
- PEngine or PE : Policy Engine
- STONITHd : Fencing daemon
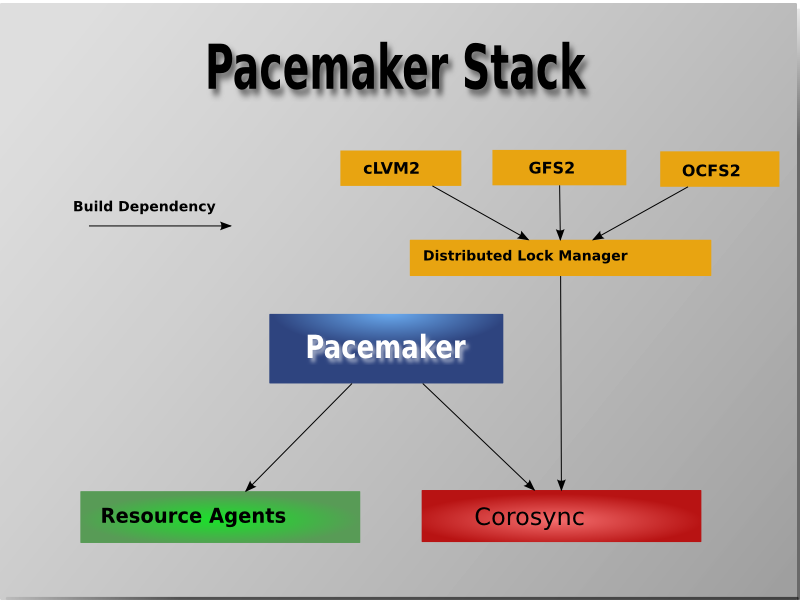
Pacemaker Stack
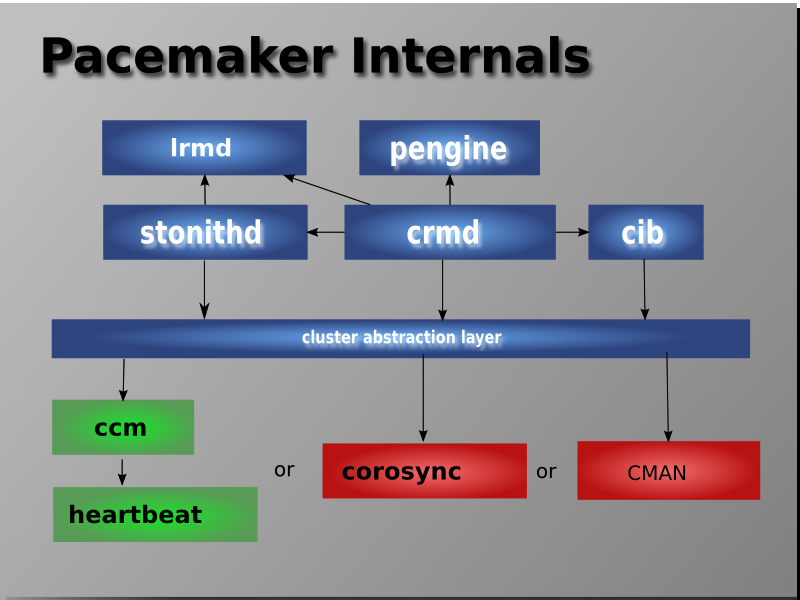
Internal Components
Linux-HA Japan Community에는 2가지 패턴 조합을 권장하고 있습니다.
- 근래 버전의 환경 : 리소스 제어로 Corosync 2.x, 클러스터 제어로 Pacemaker 1.1 (PCS : Pacemaker, Corosync configuration System)
- 오래전 버전의 환경 : 리소스 제어로 Pacemaker 1.0, 클러스터 제어로 Heartbeat 3.x
Pacemaker 클러스터 종류
- Pacemaker와 DRDB 조합의 비용 효과적인 HA 구성입니다.
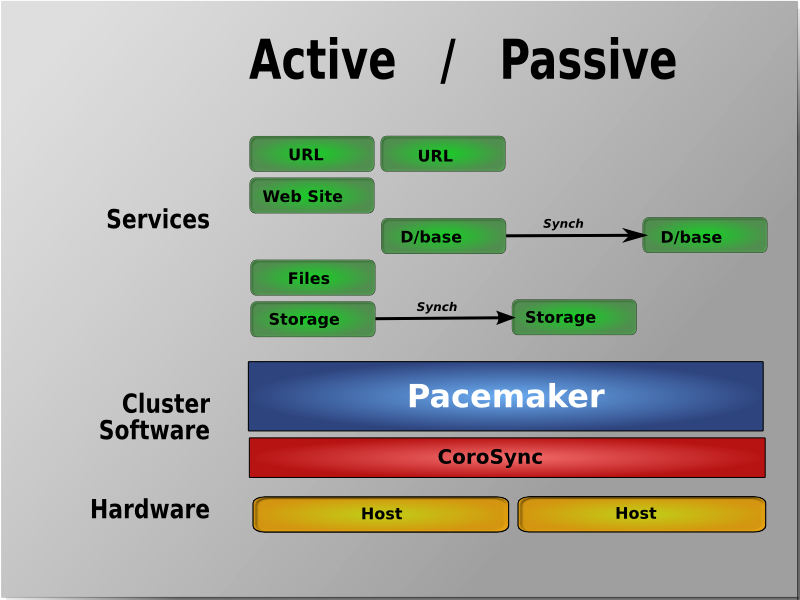
Active/Passive 이중화
- 모든 노드들은 Fail-over 구성입니다.
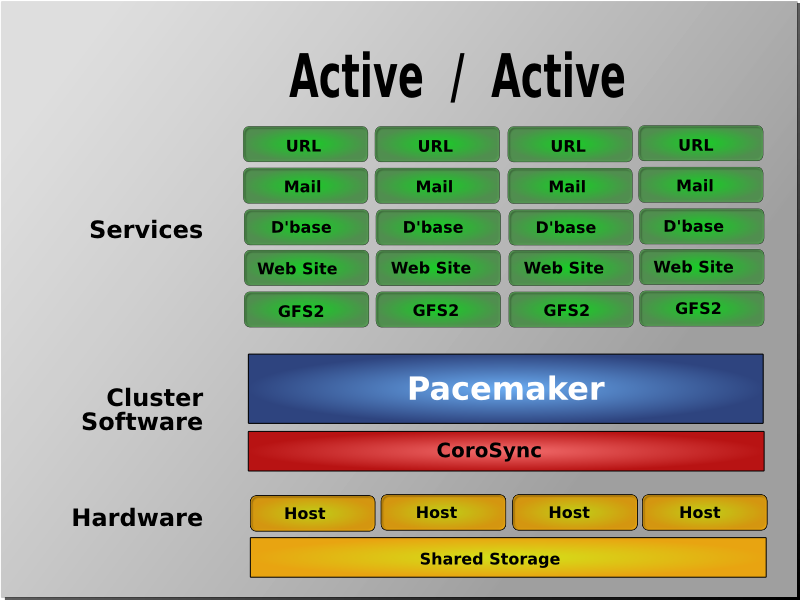
Active/Active 이중화
- Active/Passive 클러스터 구조의 공유 스토리지는 sync를 통해 하드웨어 비용절감을 상당수 절약할 수 있습니다.
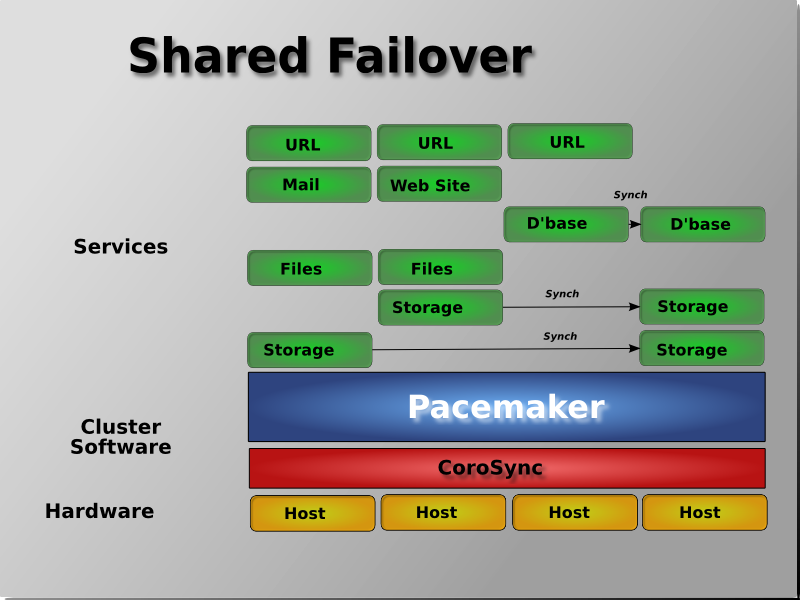
스토리지 Fail-over
Active/Passive 구조에서 ip, 서비스(http), storage(docurmnt root)의 HA 구성 후 fail-over 테스트에 대한 결과 간단한 예입니다.
환경 구성은 clusterlabs 사이트를 참고 하세요. http://clusterlabs.org/doc/en-US/Pacemaker/1.1-pcs/html-single/Clusters_from_Scratch/index.html
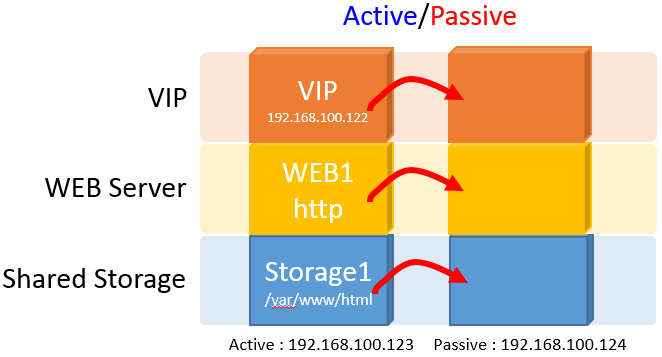
시나리오 구성도
pcmk-1(Active) : 192.168.100.123, 192.168.100.122(vip)
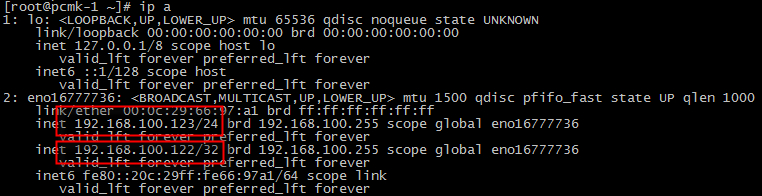
pcmk-1 service : http

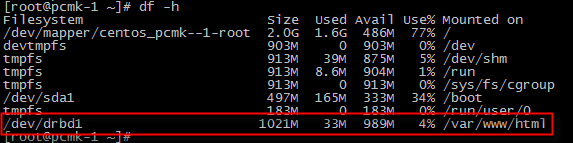
pcmk-1 storage : /var/www/html
cluster status
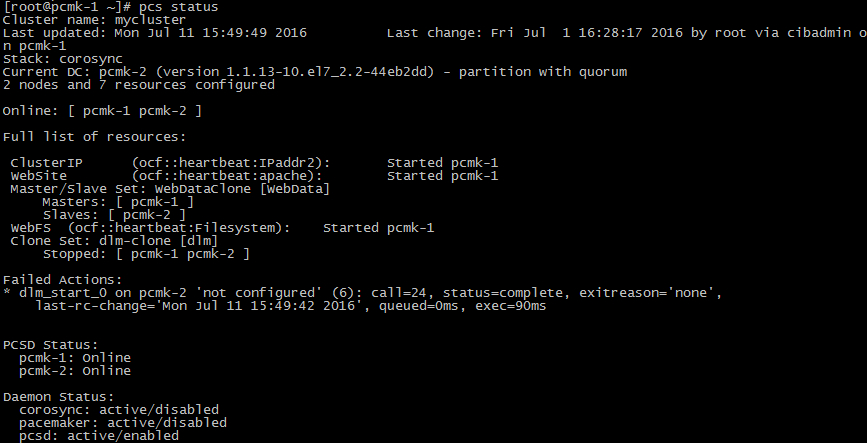
관리 리소스는 ClusterIP, WebService, WebFileSystem 입니다.
노드 pcmk-1 Active 노드에서 서비스 되고 있습니다. Passive 노드의 ip와 서비스, 스토리지 상태를 보면
pcmk-2(Passive) : 192.168.100.124
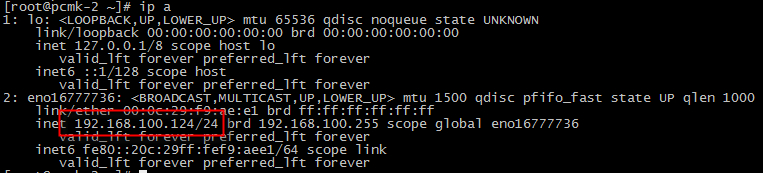
pcmk-2 service : http : 존재하지 않음

pcmk-2 storage : /var/www/html : 존재하지 않음
장애 상황을 만들어(pcmk-1 shutdown) 리소스들이 모두 fail-over 되는지 확인합니다.
pcmk-2에서 pcmk-1로 ping 테스트

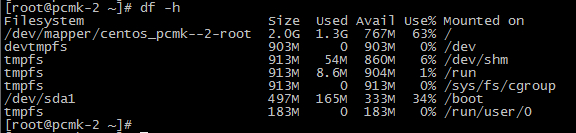
pcmk-2 IP : 192.168.100.124, 192.168.100.122(vip)
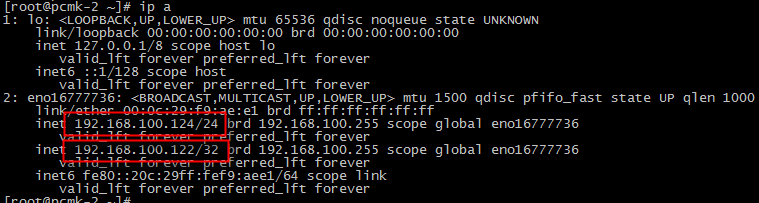
pcmk-2 service : http
pcmk-2 storage : /var/www/html
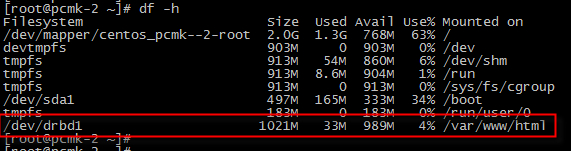
cluster status
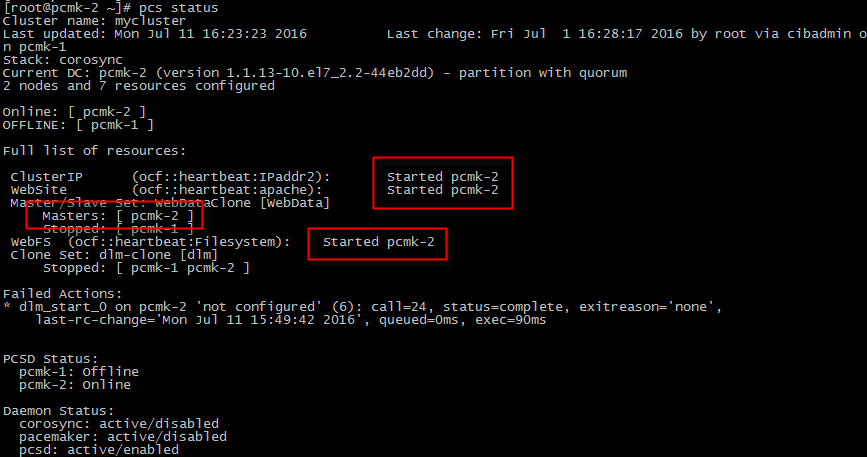
관리 리소스 ClusterIP, WebService, WebFileSystem 모두 pamk-2 서버로 fail-over 되어 pcmk-2 노드가 Master 역할을 수행합니다.
예전 VCS(Veritas Cluster Server, 현재 Veritas InfoScale)라는 솔루션을 다뤄본 적이 있습니다. Pacemaker가 상용 제품의 세세한 기능까진 포함하지 않지만 소규모 단위의 클러스터링 구성은 pacemaker만으로도 충분한 구성이 가능합니다. 현재 twitter나 instagram의 대용량 서비스(deep-dive한 구성은 필수), snapshot버전이지만 Apache Storm, OpenStack(Control Node)에 적용으로 SOA, MSA의 loose coupling 구조에서의 유연한 scaling 아키텍처에 만족할 만한 저비용 고성능 HA 솔루션이 아닐까 합니다.
[참고사이트]

