프로젝트를 수행하다 보면 고객의 요구사항을 최대한 수용해주고 싶지만 그럴 수 없는 상황을 만나곤 한다. 이번 프로젝트에서도 그러한 상황이 발생했는데 바로 빅데이터를 오라클에 저장하고 싶은 고객의 요청이 그러했다. 빅데이터 분석 프로젝트를 진행하면서 여러가지 상황을 접해 보았고 여러가지 기술들을 비교해보고 다양한 방법으로 빅데이터를 분석해 보았다. 그렇게 빅데이터 분석에 자신감이 붙었지만 위의 고객의 요구사항만큼은 시스템적으로 수용될지 확신이 서지 않았다. 이를 확인해 보기 위해서 과연 오라클이 얼마나 많은 데이터를 하루에 수용할 수 있는지 프로토 타입을 구성해서 테스트 해보기로 결정했다.
빅데이터 스토리지에 대해서 간략하게 알아보자
흔히 부르는 Big Data는 데이터가 크기가 큰 것만을 이야기 하는 것은 아니다. 데이터의 양(Volume), 형태(variety), 생성속도(velocity)도 Big Data영역에 포함된다. 이러한 Big Data를 다루는 작업은 무엇보다 저장된 데이터를 효율적으로 분석할 수 있어야 한다. 이러한 요건들을 만족시키지는 여러 가지 스토리지가 나와있는데 NoSql군에 속하는 저장소가 그러한 것들이다. NoSQL은 “Not Only SQL” 약어다. NoSQL은 데이터가 크기가 크거나 데이터가 정형화 되어 있지 않은 경우가 많아 SQL로 모든 데이터 조회가 쉽지 않으므로 자체적으로 데이터를 조회 및 분석 할 수 있는 매커니즘을 제공하는데 대표적인 것이 우리가 흔히 부르는 Map/Reduce라는 Functional한 함수 형태의 분석 매커니즘이다. 또한 NoSQL 군의 스토리지는 대부분 다루는 데이터양이 많다. 따라서 분산해서 데이터를 저장할 필요가 있으므로 분산모드를 제공하는 경우가 많다.
고객의 요구사항과 설계사이에서 갈등이 발생
정형화된 데이터가 단지 용량만 어느 정도 많이 차지할 때 RDB와 Big Data 스토리지 사이에 어느 것을 사용할지 갈등이 발생하게 된다. 하루에 정확히 얼마나 많은 데이터를 RDB가 수용될 지 모르는 상황에서 우리는 고객의 요구사항을 들어줄 수 있는지 없는지 확신이 서지 않았고 이를 해결하기 위해 과연 RDB가 얼마나 많이 데이터를 수용할 수 있는지 프로토타입을 만들어 보기로 했다. 아래는 우리가 겪은 문제점을 구체적으로 적어보았다.
고객의 목표는 약 14~15개 테이블에 약 600만~16억개씩의 Row를 매일 적재하는 것이 목표였고 하루에 적재되는 모든 테이블의 Row수를 합치면 대략 20억개의 Row가 되었다. 고객은 RDB에 데이터를 적재하기를 원했다. 정형화 되어 있는 데이터는 SQL로 얼마든지 데이터를 조회 해 볼 수 있을 것이라 생각했었던 것 같고 따라서 데이터를 24시간 안에 모든 데이터를 적재할 수 있으면 목표를 달성 할 수 있으리라 생각했던 것 같다.
Big Data를 RDB(오라클)로 적재 성능 테스트
약 14~16개의 테이블에 매일 총 20억개의 row를 쌓는 일은 리스크가 많았다. 따라서 개인적은 소견으로는 RDB보다 NoSQL군의 스토리지를 사용하기를 원했으나 뜻대로 할 수 있는 부분은 아니였다.
프로토타입 구성
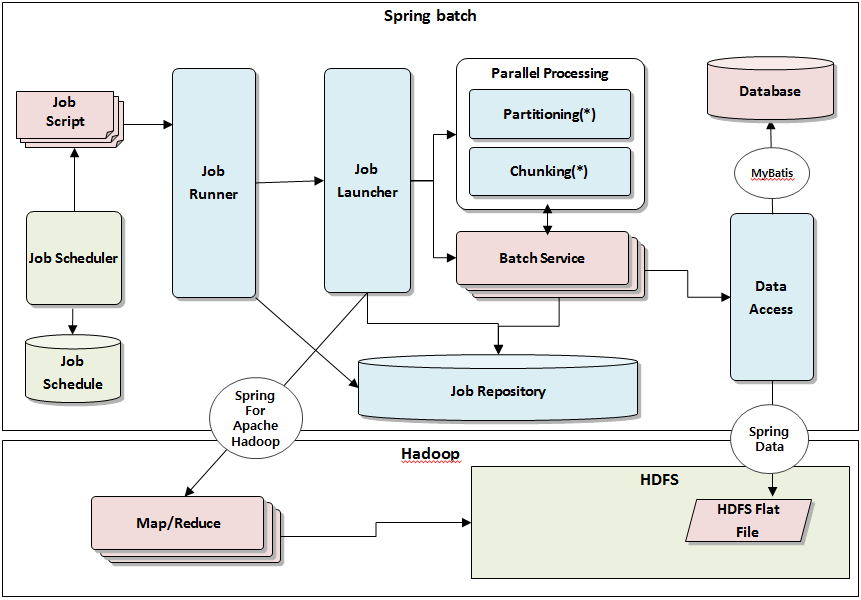
PM과 협의하여 20억개의 Row를 어떻게 처리할지 기초 설계를 수립하였다. 기초안은 Hadoop의 HDFS에 데이터가 적재되고 Hadoop의 Map/Reduce를 이용해서 테이블에 적재될 데이터를 만들고 이를 스프링 배치에서 Spring Data, Mybatis를 연동하여 데이터를 읽고 저장하도록 애플리케이션을 구성하기로 했다.
위의 프로토타입은 인력부족으로 대부분 홀로 수행하게 되었는데 약 3주정도가 지나고 나서 위의 모습대로 프로토타입을 만들 수 있었다. 완성된 애플리케이션은 생각보다 굉장히 만족도가 높았다
스프링 배치와 하둡의 연동(Map/Reduce 및 HDFS 연동)은 Spring For Apache Hadoop과 Spring Data를 사용해서 처리하였는데 특별히 버그를 발견할 수 없었고 스프링과 Hadoop을 잘 연계시켜 주었다.
위의 애플리케이션 수행절차는 다음과 같다.
- HDFS에 적재된 로그를 기반으로 Map/Reduce를 수행하여 14개 테이블에 적재될 수 있는 데이터를 HDFS에 생성한다.
- HDFS 생성된 데이터를 스프링 배치에서 읽어 MyBatis 배치모드로 데이터를 적재한다.
RDB에 적재테스트 환경
- DB는 오라클이고 대기업의 실제 운영DB(사양을 정확히 공개하지는 않겠다)를 기준으로 테스트를 수행.
- 적재에 필요한 기술셋으로는 Spring Data, Mybatis, Spring Batch를 적용
- DB는 적재 성능 측정은 단일 쓰래드를 사용함
- commit Interval은 10000을 적용
테스트 결과 정리
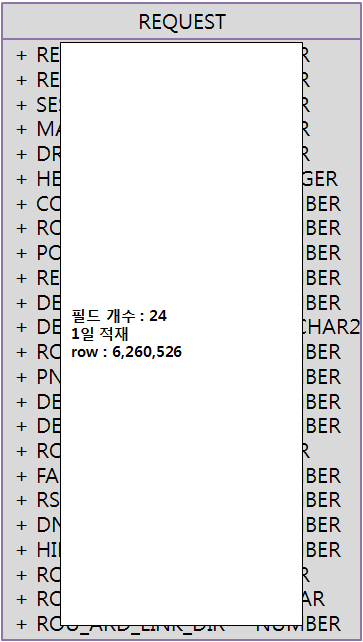
적재 대상 테이블

적재대상 데이터
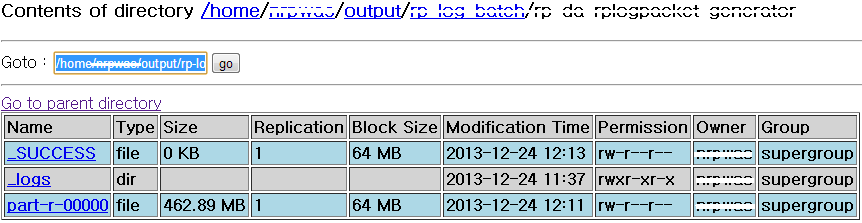
내용

결과

단일 쓰래드로 총 6,260,526 row를 7개의 컬럼을 가지는 테이블에 적재하는데 총 6분 27초 소요되었다.
적재 대상 테이블
적재대상 데이터
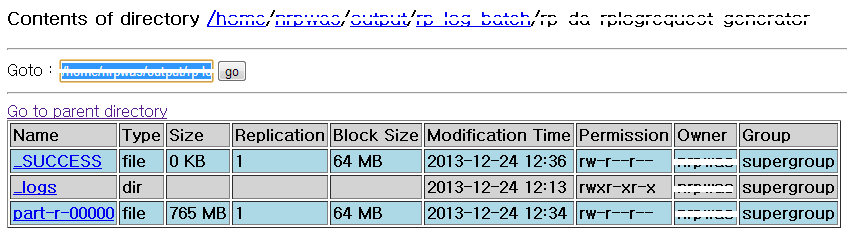
내용
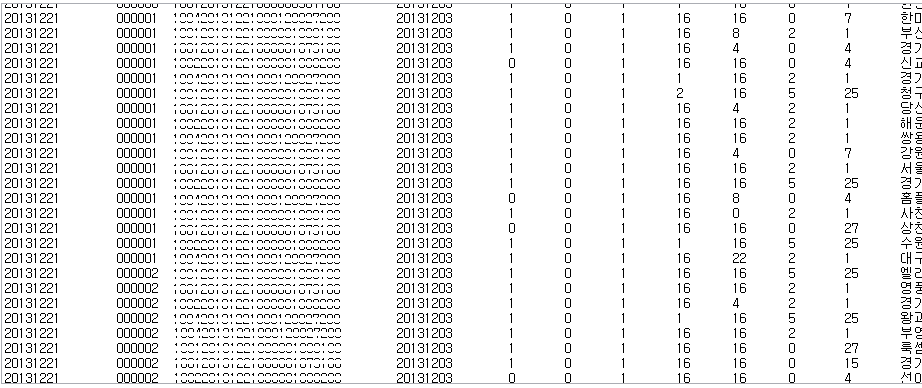
결과

단일 쓰래드로 총 6,260,526 row를 24개의 컬럼을 가지는 테이블에 적재하는데 총 8분 55초 소요되었다.
적재 대상 테이블

적재대상 데이터
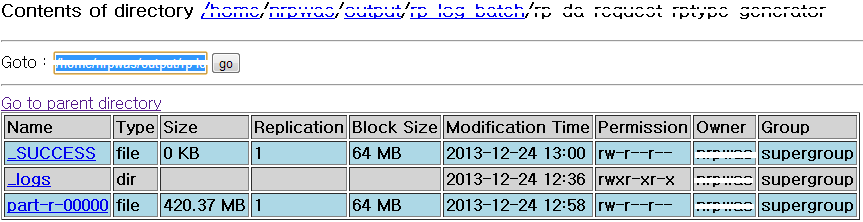
내용

결과

단일 쓰래드로 총 9,794,449 row를 5개의 컬럼을 가지는 테이블에 적재하는데 총 6분 1초 소요되었다.
적재 대상 테이블
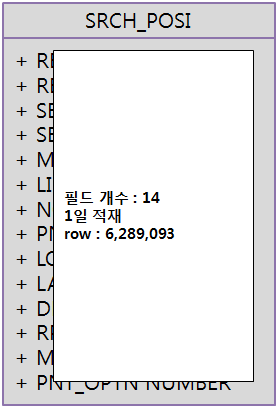
적재대상 데이터
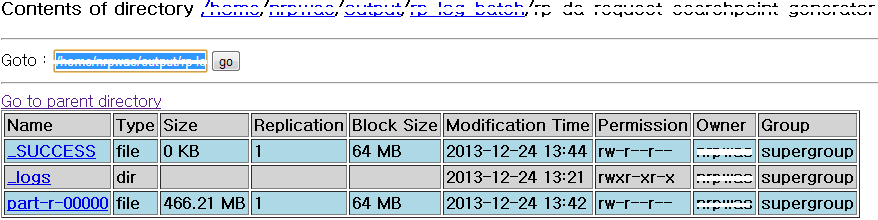
내용
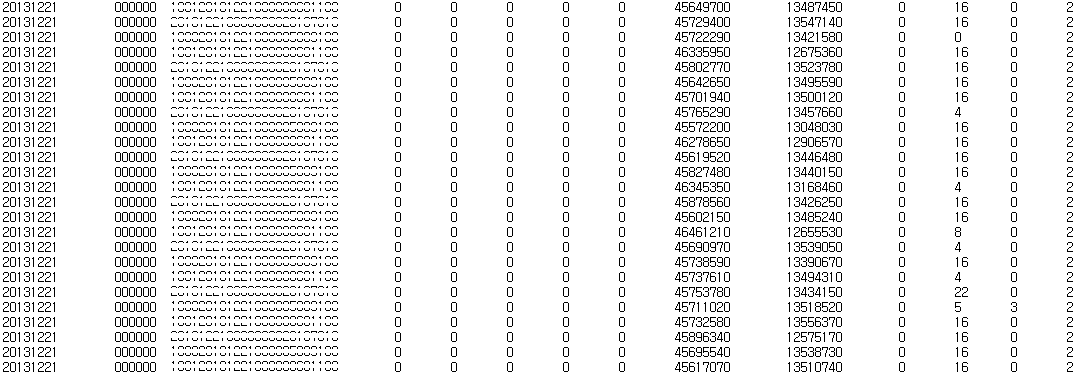
결과

단일 쓰래드로 총 6,286,093 row를 14개의 컬럼을 가지는 테이블에 적재하는데 총 5분 31초 소요되었다.
적재 대상 테이블

적재대상 데이터
내용

결과

단일 쓰래드로 총 393,778 row를 6개의 컬럼을 가지는 테이블에 적재하는데 총 16초 소요되었다.
적재 대상 테이블

적재대상 데이터
내용
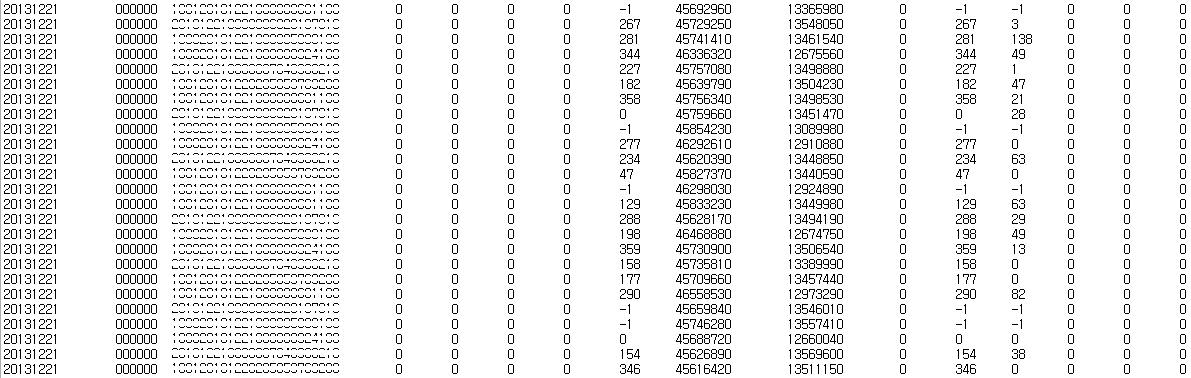
결과

단일 쓰래드로 총 6,260,526 row를 17개의 컬럼을 가지는 테이블에 적재하는데 총 6분 5초 소요되었다.
적재 대상 테이블
적재대상 데이터
내용

결과

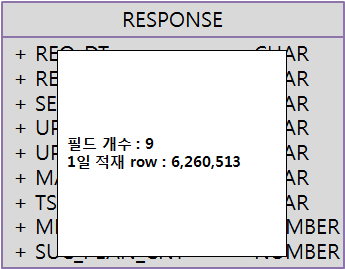
단일 쓰래드로 총 6,260,513 row를 9개의 컬럼을 가지는 테이블에 적재하는데 총 8분 1초 소요되었다.
적재 대상 테이블

적재대상 데이터
내용
결과

단일 쓰래드로 총 9,794,410 row를 8개의 컬럼을 가지는 테이블에 적재하는데 총 6분 33초 소요되었다.
적재 대상 테이블

적재대상 데이터
내용
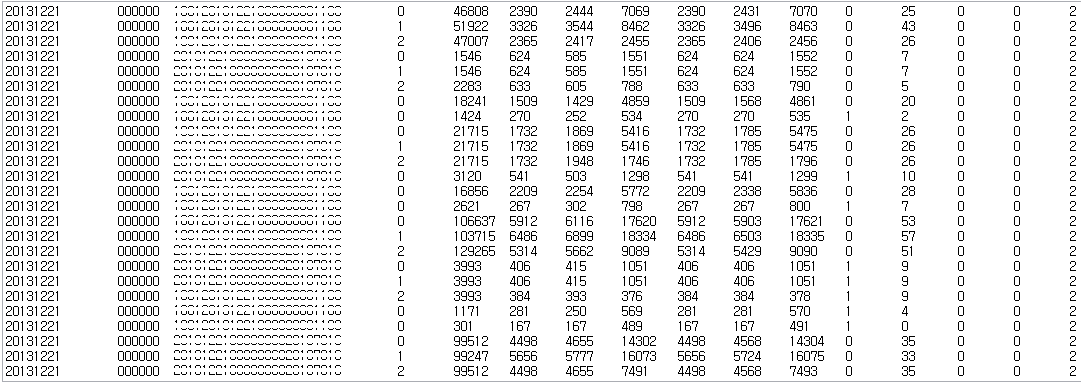
결과

단일 쓰래드로 총 9,794,575 row를 17개의 컬럼을 가지는 테이블에 적재하는데 총 8분 42초 소요되었다.
적재 대상 테이블

적재대상 데이터
내용
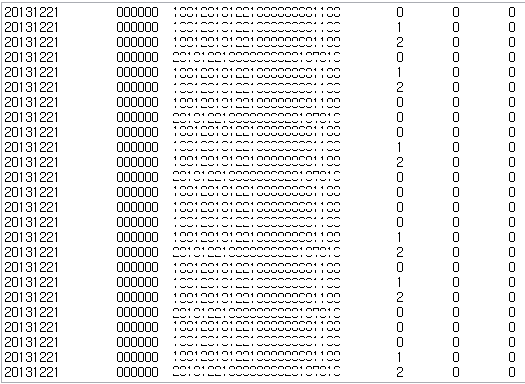
결과

단일 쓰래드로 총 9,794,565 row를 8개의 컬럼을 가지는 테이블에 적재하는데 총 6분 52초 소요되었다.
적재 대상 테이블

적재대상 데이터
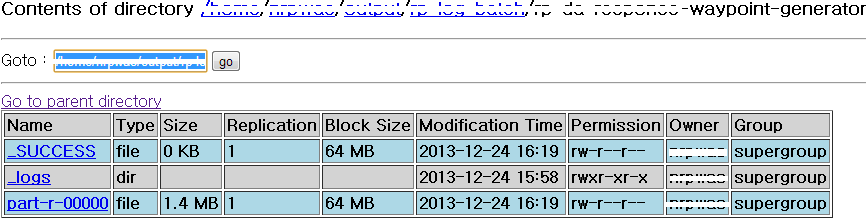
내용
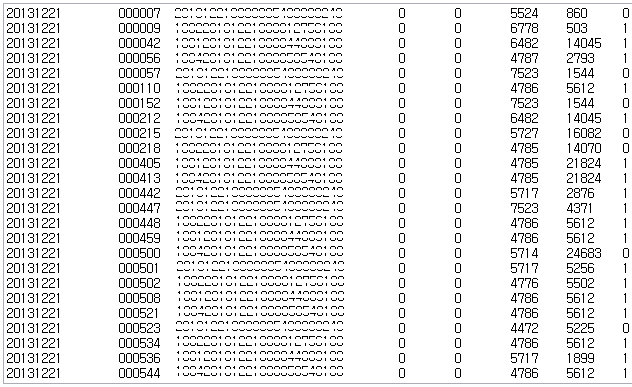
결과

단일 쓰래드로 총 25,580 row를 8개의 컬럼을 가지는 테이블에 적재하는데 총 1초 소요되었다.
적재 대상 테이블

적재대상 데이터
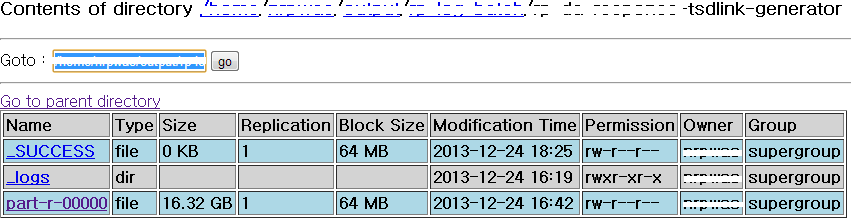
내용
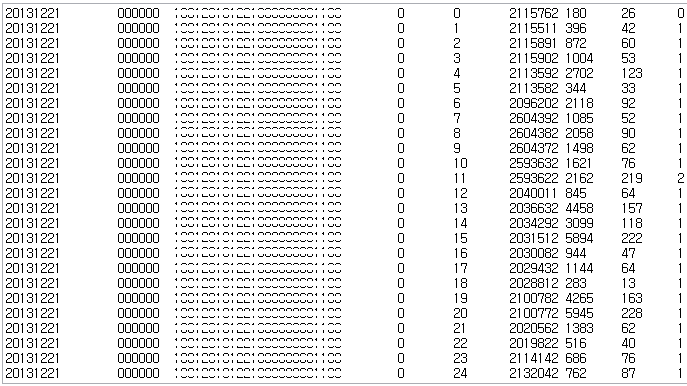
결과
단일 쓰래드로 총 276,179,101 row를 9개의 컬럼을 가지는 테이블에 적재하는데 약 5~6 시간 소요된다.
적재대상 데이터

결과
컬럼이 31개인 16억개의 row는 앞서 테스트한 TSD_LINK의 최소 20배 이상의 데이터 크기를 가진다.
이는 단일 쓰래드로 테스트가 불가능하고 의미조차 없다. TSD가 약 6시간정도 소요되는걸 감안했을 때 16억개의 row는 처리가 불가능하다. 따라서 테스트는 생략했다.
테스트를 마치면서
프로토타입을 마친 후 PM과 고객이 함께 모여서 위의 결과를 놓고 토론를 했다. 하루 20억 Row를 오라클에 적재하는 일은 여러가지 문제점이 많다는 사실을 고객이 이해했고 다른 방법으로 위의 문제를 풀기로 결정을 내렸다. 위의 프로토타입을 수행함으로서 고객의 요구사항을 들어줄 수 없다는 결정을 이끌어 내게 되어서 개인적으로 좀 안타까웠다. 하지만 이렇게 테스트를 수행함으로써 고객과 원할한 소통을 할 수 있었고 이 내용을 공유함으로써 다른 사람이 나와 같은 고민을 하지 않아도 된다고 생각하니 조금은 마음의 위안이 된다.
프로토 타입 구성 방법을 아래에 간략히 정리한다.
필요한 라이브러리 설정
스프링과 Hadoop을 연계하기 위해서 Maven에 아래와 같은 dependency를 추가
<!-- spring for apache hadoop -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.0.1</version>
</dependency>
<dependency>
<groupId>org.codehaus.groovy</groupId>
<artifactId>groovy</artifactId>
<version>1.8.5</version>
</dependency>
<!-- spring data -->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-hadoop</artifactId>
<version>1.0.1.RELEASE</version>
</dependency>
Hadoop에서 제공하는 HDFS 및 Map/Reduce를 사용하기 위해서 Hadoop 정보를 스프링에 설정
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:hdp="http://www.springframework.org/schema/hadoop"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/hadoop http://www.springframework.org/schema/hadoop/spring-hadoop.xsd">
<hdp:configuration>
fs.default.name=${hd.fs}
mapred.job.tracker=${hd.jt}
</hdp:configuration>
<hdp:resource-loader id="hadoopResourceLoader" />
</beans>
Hadoop의 Map/Reduce를 Spring배치와 연동하기 위해 Tasklet 설정
<?xml version="1.0" encoding="UTF-8"?>
<beans:beans
xmlns="http://www.springframework.org/schema/hadoop"
xmlns:beans="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/hadoop http://www.springframework.org/schema/hadoop/spring-hadoop.xsd">
<!-- map/Reduce pre-action script -->
<script-tasklet id="pre-action-tasklet" script-ref="pre-action-script" scope="step"/>
<script id=" pre-action-script" location="script/pre-action.groovy">
<property name="outputDir" value="${job.hdfs.output.root.location}"/>
</script>
<!-- data generation job -->
<job-tasklet id="data-generation-tasklet" job-ref="data-generation-job"/>
<job id="data-generation-job"
input-path="${job.hdfs.input.root.location}/#{jobParameters['mr.input']}"
output-path="${job.data.generator.hdfs.output.location}"
mapper="generator.data.mapreduce.DataGeneratorMapper"
reducer=" generator.data.mapreduce.DataGeneratorReducer"
libs="file:${job.data.generator.jars.location}/*.jar"
scope="step" />
</beans:beans>
맵리듀스 pre Action 스크립트(pre-action-script) 파일
스크립트로 HDFS파일을 다룰 수 있다. 필요에 따라서 Map/Reduce를 수행하거나 또는 수행한 후 데이터를 지우거나 삭제하거나 데이터를 위치를 옮길 수 있다
if (fsh.test(outputDir)) {
fsh.rmr(outputDir)
}
HDFS에서 데이터를 읽도록 ResourceItemReader를 구성
<bean id="hdfsMultiResourceItemReader" class="HdfsMultiResourceItemReader" scope="step" >
<constructor-arg>
<list>
<value>${job.data.generator.hdfs.output.location}/part-r-00000</value>
</list>
</constructor-arg>
<constructor-arg ref="hadoopResourceLoader"/>
<property name="delegate" ref="dataFlatFileItemReader"/>
</bean>
<bean id=" dataFlatFileItemReader” class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="lineMapper">
<bean class="DataLineMapper"/>
</property>
</bean>
<bean id="rpLogPacketWriter" class="DataWriter" />
Spring Data에서 제공하는 HdfsResourceLoader를 사용하여 스프링 배치에서 HDFS파일을 바로 억세스 할 수 있도록 MultiResourceItemReader를 구성
public class HdfsMultiResourceItemReader<T> extends MultiResourceItemReader<T> {
/**
* 리소스 리스트
*/
private List<String> resourceList;
/**
* 리소스 로더
*/
private HdfsResourceLoader hdfsResourceLoader;
/**
* 기본 생성자
*/
public HdfsMultiResourceItemReader(){
super();
}
/**
* 생성자
*
* @param resourceList
* @param hdfsResourceLoader
*/
public HdfsMultiResourceItemReader(List<String> resourceList, HdfsResourceLoader hdfsResourceLoader) {
super();
this.resourceList = resourceList;
this.hdfsResourceLoader = hdfsResourceLoader;
init();
}
/**
* 초기화
*/
public void init(){
if(resourceList == null || resourceList.size() == 0) return;
Resource[] resources = new Resource[resourceList.size()];
for(int i=0; i<resourceList.size(); i++){
resources[i] = hdfsResourceLoader.getResource(resourceList.get(i));
}
super.setResources(resources);
}
}
Spring Batch와 Hadoop을 연계한 워크플로우를 작성
<?xml version="1.0" encoding="UTF-8"?>
<beans:beans
xmlns="http://www.springframework.org/schema/hadoop"
xmlns:beans="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/hadoop http://www.springframework.org/schema/hadoop/spring-hadoop.xsd">
<batch:job id="rplog-persist-rdb">
<!-- pre-action -->
<batch:step id="pre-action" next="data-generation">
<batch:tasklet ref="pre-action-tasklet"/>
</batch:step>
<!-- generate data -->
<batch:step id="data-generation" next="data-rdb-persistence">
<batch:tasklet ref="data-generation-tasklet" />
</batch:step>
<!-- persist data -->
<batch:step id="data-rdb-persistence" parent="hdfs-rdb-persistence">
<batch:tasklet>
<batch:chunk reader="hdfsMultiResourceItemReader" writer="dataWriter">
<batch:skippable-exception-classes>
<batch:include class="SkipException" />
</batch:skippable-exception-classes>
</batch:chunk>
</batch:tasklet>
</batch:step>

