현재를 살아가는 우리들은 모두 일정한 원리/원칙 아래에서 생활하고 있습니다. 여기서의 원칙 이라 함은 좁은 의미로는 개개인의 사고방식이나 신념, 가치관 정도가 될 수가 있겠고, 넓게는 한 국가의 통치 이념이나 통치 방법 정도가 되겠습니다. 그럼 우리는 왜 이런 원칙들 아래에서 생활하고 있는 걸까요? 이거다라고 단정할 수는 없지만 그건 아마도 그런 원칙들이 개인의 삶을 윤택하게 하고 국민들의 삶의 질을 향상 시키는 데 보다 효율적이고 효과적이기 때문입니다.
마찬가지로 입증된 객체지향 디자인 원리들을 사용하면 좀 더 유지보수하기 쉽고, 유연하고, 확장이 쉬운 소프트웨어를 만들 수 있습니다. 이 원리들은 그 크기를 대비해 보면 패턴보다 훨씬 작지만 표준화 작업에서부터 아키텍처 설계에 이르기까지 다양하게 적용되는 원칙입니다. 초로의 나이이임도 불구하고 태극권의 일인자였던 어느 노인이 이런 말을 했다고 합니다. “나는 한평생을 걸쳐 무술을 연습했지만 이제 서기(자세)를 제대로 할 수 있을 것 같다.” 입문자 때 배우는 서기 자세는 아주 쉬운 것 같지만 역설적이게도 아주 어렵다고 합니다. 우리에게 있어서 객체지향 설계 원칙이 서기(자세) 정도의 의미가 아닐까 생각됩니다. 따라서 이번 시간에는 이런 입증된 원리들에 대해서 알아 봅니다.
1. 5가지 원리의 핵심내용
A. SRP (단일책임의 원칙: Single Responsibility Principle)
THERE SHOULD NEVER BE MORE THAN ONE REASON FOR A CLASS TO CHANGE.
i. 정의
작성된 클래스는 하나의 기능만 가지며 클래스가 제공하는 모든 서비스는 그 하나의 책임(변화의 축: axis of change)을 수행하는 데 집중되어 있어야 한다는 원칙입니다. 이는 어떤 변화에 의해 클래스를 변경해야 하는 이유는 오직 하나뿐이어야 함을 의미합니다. SRP원리를 적용하면 무엇보다도 책임 영역이 확실해지기 때문에 한 책임의 변경에서 다른 책임의 변경으로의 연쇄작용에서 자유로울 수 있습니다. 뿐만 아니라 책임을 적절히 분배함으로써 코드의 가독성 향상, 유지보수 용이라는 이점까지 누릴 수 있으며 객체지향 원리의 대전제 격인 OCP원리뿐 아니라 다른 원리들을 적용하는 기초가 됩니다. 이 원리는 다른 원리들에 비해서 개념이 비교적 단순하지만, 이 원리를 적용해서 직접 클래스를 설계하기가 그리 쉽지만은 않습니다. 왜냐하면, 실무의 프로세스는 매우 복잡 다양하고 변경 또한 빈번하기 때문에 경험이 많지 않거나 도메인에 대한 업무 이해가 부족하면 나도 모르게 SRP원리에서 멀어져 버리게 됩니다. 따라서 평소에 많은 연습(‘책임’이란 단어를 상기하는)과 경험이 필요한 원칙입니다.
ii. 적용방법
리팩토링(Refactoring: Improving the Design of Existing Code -Martin Fowler)에서 소개하는 대부분의 위험상황에 대한 해결방법은 직/간접적으로 SRP원리와 관련이 있으며, 이는 항상 코드를 최상으로 유지한다는 리팩토링의 근본정신도 항상 객체들의 책임을 최상의 상태로 분배한다는 것에서 비롯되기 때문입니다.
여러 원인에 의한 변경 (Divergent change): Extract Class를 통해 혼재된 각 책임을 각각의 개별 클래스로 분할하여 클래스 당 하나의 책임만을 맡도록 하는 것입니다. 여기서 관건은 책임만 분리하는 것이 아니라 분리된 두 클래스간의 관계의 복잡도를 줄이도록 설계하는 것입니다. 만약 Extract Class된 각각의 클래스들이 유사하고 비슷한 책임을 중복해서 갖고 있다면 Extract Superclass를 사용할 수 있습니다. 이것은 Extract된 각각의 클래스들의 공유되는 요소를 부모 클래스로 정의하여 부모 클래스에 위임하는 기법입니다. 따라서 각각의 Extract Class들의 유사한 책임들은 부모에게 명백히 위임하고 다른 책임들은 각자에게 정의할 수 있습니다.
산탄총 수술(Shotgun surgery): Move Field와 Move Method를 통해 책임을 기존의 어떤 클래스로 모으거나, 이럴만한 클래스가 없다면 새로운 클래스를 만들어 해결할 수 있습니다. 즉 산발적으로 여러 곳에 분포된 책임들을 한 곳에 모으면서 설계를 깨끗하게 합니다. 즉 응집성을 높이는 작업입니다.
iii. 적용사례
[그림1.]의 간단한 클래스를 보겠습니다. 변화가 예상되는 부분이 보이시나요? 천천히 살펴보도록 하겠습니다.

위 [그림1.]에서 보는 바와 같이 serialNumber는 변화요소라 할 수 없고 단지 고유정보라고 할 수 있습니다. 동종의 다른 클래스와 구분되는 정보라고 할 수 있겠네요. 그리고 price와 Maker, Type, model, backWood, topWood, stringNum 등은 모두 특성 정보군으로 변경이 발생 할 수 있는 부분이라 할 수 있고, 이 부분은 변화 요소로 예상이 됩니다. 따라서 특정 정보군에 변화가 발생하면 항상 해당 클래스를 수정해야 하는 부담이 발생하게 됨으로 이 부분이 SRP적용의 대상이 됩니다.
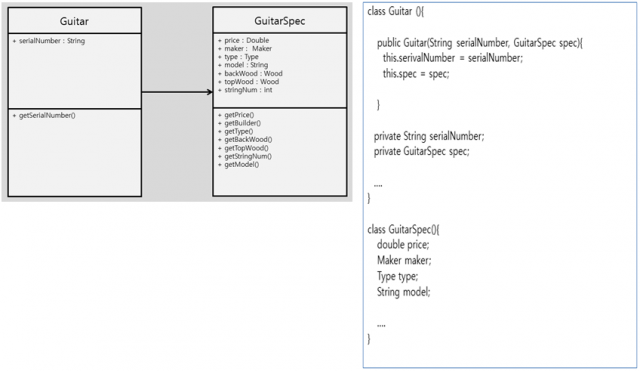
위[그림2. ]의 다이어그램을 보면 변화가 예상되는 특성 정보군을 분리한 것을 확인 하실 수 있습니다. 따라서 특성 정보에 변경이 일어나면 GuitarSpec 클래스만 변경하면 됩니다. 훨씬 보기에도 좋아졌고 무엇보다 변화에의해 변경되는 부분을 한곳에서 관리할 수 있게 되었습니다.
iv. 적용이슈
클래스는 자신의 이름이 나타내는 일을 해야 합니다. 올바른 클래스 이름은 해당 클래스의 책임을 나타낼 수 있는 가장 좋은 방법입니다.
각 클래스는 하나의 개념을 나타내어야 합니다.
사용되지 않는 속성이 결정적 증거입니다.
무조건 책임을 분리한다고 SRP가 적용되는 건 아닙니다. 각 개체 간의 응집력이 있다면 병합이 순 작용의 수단이 되고 결합력이 있다면 분리가 순 작용의 수단이 됩니다.
B. OCP (개방폐쇄의 원칙: Open Close Principle)
YOU SHOULD BE ABLE TO EXTEND A CLASSES BEHAVIOR, WITHOUT MODIFYING IT.
i. 정의
버틀란트 메이어(Bertrand Meyer)박사가 1998년 객체지향 소프트웨어 설계 라는 책에서 정의한 내용으로 소프트웨어의 구성요소(컴포넌트, 클래스, 모듈, 함수)는 확장에는 열려있고, 변경에는 닫혀있어야 한다는 원리입니다. 이것은 변경을 위한 비용은 가능한 줄이고 확장을 위한 비용은 가능한 극대화 해야 한다는 의미로, 요구사항의 변경이나 추가사항이 발생하더라도, 기존 구성요소는 수정이 일어나지 말아야 하며, 기존 구성요소를 쉽게 확장해서 재사용할 수 있어야 한다는 뜻입니다. 로버트 C. 마틴은 OCP는 관리가능하고 재사용 가능한 코드를 만드는 기반이며, OCP를 가능케 하는 중요 메커니즘은 추상화와 다형성이라고 설명하고 있습니다. OCP는 객체지향의 장점을 극대화하는 아주 중요한 원리라 할 수 있습니다.
ii. 적용방법
- 변경(확장)될 것과 변하지 않을 것을 엄격히 구분합니다.
- 이 두 모듈이 만나는 지점에 인터페이스를 정의합니다.
- 구현에 의존하기보다 정의한 인터페이스에 의존하도록 코드를 작성 합니다.
iii. 적용사례
위에서도 보았던 간단한 클래스 다이어그램입니다.
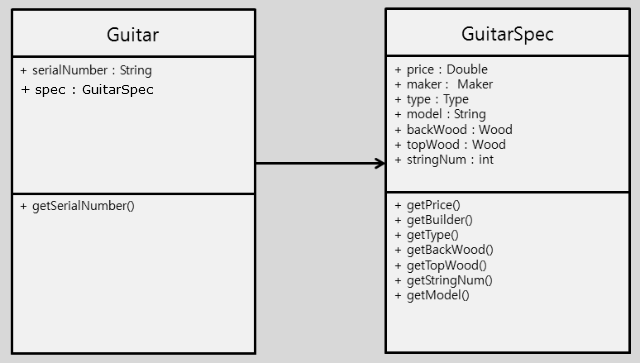
별 문제가 없어 보입니다. SRP원리를 적용하여 Guitar에서 변경이 예상되는 부분을 뽑아 GuitarSpec이라는 새로운 클래스를 만들어 변화요소들을 하나로 모았습니다. 변화를 국소화 시켰습니다. 하지만 여기에서도 변경이 발생할 수 있습니다. 예를 들어 아래와 같이 Guitar이 외에 바이올린이나 첼로, 비올라, 만돌린과 같은 다른 악기들도 다루어야 한다면 어떻게 될까요? 그 해결책으로 만일 아래[그림4.]와 같이 일일이 매번 새로운 악기들과 요소들을 만들어 간다면 어떻게 될까요? 우리는 항상 변화를 염두해 두고 있어야 합니다.
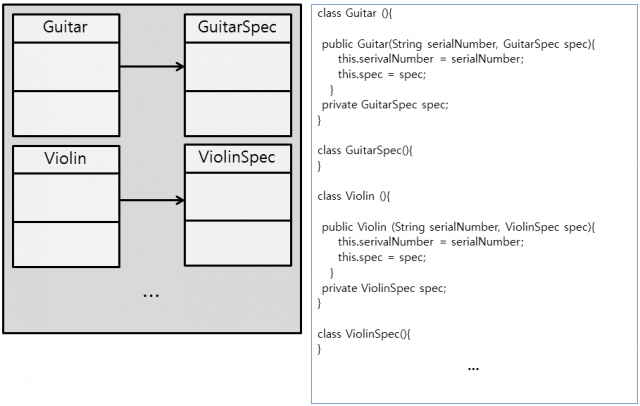
변화를 막을 수 있는 사람은 아무도 없습니다. 다만 변화에 적절히 대응할 뿐입니다. 위와 같이 변화에 몸을 맡겨버린다면 엄청난 재앙이 두고두고 여러 개발자들을 괴롭힐 것입니다. 자 이제 지구를 구하는 심정으로 그럼 앞서 설명한OCP원리를 이용하여 위와 같은 변화에 대응해 보도록 합니다.
먼저, Guitar와 추가 될 다른 악기들을 추상화하는 작업이 필요합니다. 여기서는 추가될 악기들의공통 속성을 모두 담을 수 있는 StringInstrument라는 인터페이스를 생성하겠습니다. 앞으로는 StringInstrument가 이들을 대표하게 될 것입니다. 아래[그림 5.]는 OCP원리가 적용된 다이어그램과 소스를 나타냅니다.
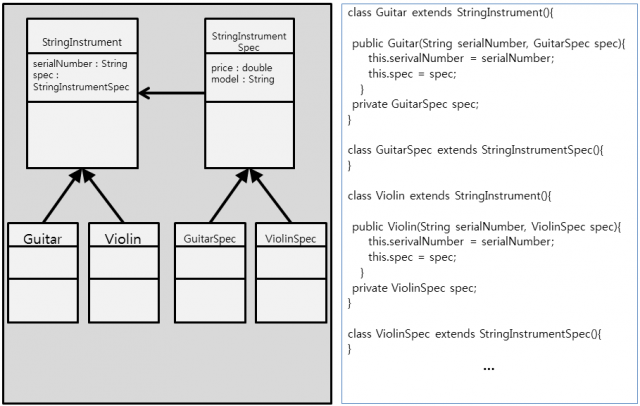
새로운 악기가 추가 되면서 변경이 발생하는 부분을 추상화 하여 분리하였음을 확인 할 수 있습니다. 이렇게 해서 코드의 수정을 최소화하여 결합도는 줄이고 응집도는 높이는 효과를 볼 수 있습니다.
iv. 적용이슈
확장되는 것과 변경되지 않는 모듈을 분리하는 과정에서 크기 조절에 실패하면 오히려 관계가 더 복잡해 질 수 있습니다. 설계자의 좋은 자질 중 하나는 이런 크기 조절과 같은 갈등 상황을 잘 포착하여 (아깝지만) 비장한 결단을 내릴 줄 아는 능력에 있습니다.
인터페이스는 가능하면 변경되어서는 안 됩니다. 따라서 인터페이스를 정의할 때 여러 경우의 수에 대한 고려와 예측이 필요합니다. 물론 과도한 예측은 불필요한 작업을 만들고, 보통 이 불필요한 작업의 양은 상당히 크기 마련입니다. 따라서 설계자는 적절한 수준의 예측 능력이 필요한데, 설계자에게 필요한 또 하나의 자질은 예지력입니다.
인터페이스 설계에서 적당한 추상화 레벨을 선택해야 합니다. 우리는 추상화라는 개념에 '구체적이지 않은' 정도의 의미로 약간 느슨한 개념을 갖고 있습니다. 그래디 부치(Grady Booch)에 의하면 ‘추상화란 다른 모든 종류의 객체로부터 식별될 수 있는 객체의 본질적인 특징’이라고 정의하고 있습니다. 즉, 이 '행위'에 대한 본질적인 정의를 통해 인터페이스를 식별해야 합니다.
C. LSP (리스코브 치환의 원칙: The Liskov Substitution Principle)
FUNCTIONS THAT USE POINTERS OR REFERENCES TO BASE CLASSES MUST BE ABLE TO USE OBJECTS OF DERIVED CLASSES WITHOUT KNOWING IT.
i. 정의
이 원칙은 5가지 원칙 중에서 좀처럼 쉽게 이해 되지 않는 원칙의 하나로 LSP라는 이름에서는 도저히 원칙에 대한 내용을 도출 할 수 없는 원칙입니다. LSP를 한마디로 한다면, “서브 타입은 언제나 기반 타입으로 교체할 수 있어야 한다.”라고 할 수 있습니다. 즉, 서브 타입은 언제나 기반 타입과 호환될 수 있어야 합니다. 달리 말하면 서브 타입은 기반 타입이 약속한 규약(public 인터페이스, 물론 메소드가 던지는 예외까지 포함됩니다.)을 지켜야 합니다. 상속은 구현상속(extends 관계)이든 인터페이스 상속(implements 관계)이든 궁극적으로는 다형성을 통한 확장성 획득을 목표로 합니다. LSP원리도 역시 서브 클래스가 확장에 대한 인터페이스를 준수해야 함을 의미합니다. 다형성과 확장성을 극대화 하려면 하위 클래스를 사용하는 것보다는 상위의 클래스(인터페이스)를 사용하는 것이 더 좋습니다. 일반적으로 선언은 기반 클래스로 생성은 구체 클래스로 대입하는 방법을 사용합니다. 생성 시점에서 구체 클래스를 노출시키기 꺼려질 경우 생성 부분을 Abstract Factory 등의 패턴을 사용하여 유연성을 높일 수 있습니다. 상속을 통한 재사용은 기반 클래스와 서브 클래스 사이에 IS-A관계가 있을 경우로만 제한 되어야 합니다. 그 외의 경우에는 합성(composition)을 이용한 재사용을 해야 합니다. 상속은 다형성과 따로 생각할 수 없습니다. 그리고 다형성으로 인한 확장 효과를 얻기 위해서는 서브 클래스가 기반 클래스와 클라이언트 간의 규약(인터페이스)를 어겨서는 안 됩니다. 결국 이 구조는 다형성을 통한 확장의 원리인 OCP를 제공 하게 됩니다. 따라서 LSP는 OCP를 구성하는 구조가 됩니다. 객체지향 설계 원리는 이렇게 서로가 서로를 이용하기도 하고 포함하기도 하는 특징이 있습니다. LSP는 규약을 준수하는 상속구조를 제공 합니다. LSP를 바탕으로 OCP는 확장하는 부분에 다형성을 제공해 변화에 열려있는 프로그램을 만들 수 있도록 합니다.
ii. 적용방법
- 만약 두 개체가 똑 같은 일을 한다면 둘을 하나의 클래스로 표현하고 이들을 구분할 수 있는 필드를 둡니다.
- 똑같은 연산을 제공하지만, 이들을 약간씩 다르게 한다면 공통의 인터페이스를 만들고 둘이 이를 구현 합니다. (인터페이스 상속)
- 공통된 연산이 없다면 완전 별개인 2개의 클래스를 만듭니다.
- 만약 두 개체가 하는 일에 추가적으로 무언가를 더 한다면 구현 상속을 사용합니다.
iii. 적용사례
컬렉션 프레임워크
지난 시간에 자료구조 기억하시죠? 잠깐 기억을 떠올려 보시죠. 기억이 가물가물 하시면 한번 살펴보세요. (http://www.nextree.co.kr/p6506/)
void f(){
LinkedList list = new LinkedList();
// …
modify(list);
}
void modify(LinkedList list){
list.add(…);
doSomethingWith(list);
}
List만 사용할 것이라면 이 코드도 문제는 없습니다. 하지만 만약 속도 개선을 위해 HashSet을 사용해야 하는 경우가 발생한다면 LinkedList를 다시 HashSet으로 어떻게 바꿀 수 있을까요? LinkedList와 HashSet은 모두 Collection인터페이스를 상속하고 있으므로 다음과 같이 작성하는 것이 바람직합니다.
void f(){
Collection collection = new HashSet();
//…
modify(list);
}
Void modify(Collection collection){
collection.add(…);
doSomethingWith(collection);
}
이제 컬렉션 생성 부분만 고치면 마음대로 어떤 컬렉션 구현 클래스든 사용할 수 있습니다. 이 프로그램에서 LSP와 OCP 모두를 찾아볼 수 있는데 우선 컬렉션 프레임워크가 LSP를 준수하지 않았다면 Collection 인터페이스를 통해 수행하는 범용 작업이 제대로 수행될 수 없습니다. 하지만 모두 LSP를 준수하기 때문에 이들을 제외한 모든 Collection 연산에서는 앞의 modify() 메소드가 잘 동작하게 됩니다. 그리고 이를 통해 modify()는 변화에 닫혀 있으면서, 컬렉션의 변경과 확장에는 열려 있는 구조(OCP)가 됩니다. 물론 Collection이 지원하지 않는 연산을 사용한다면 한 단계 계층 구조를 내려가야 합니다. 그렇다 하더라도 ArrayList, LinkedList, Vector 대신 이들이 구현하고 있는 List를 사용하는 것이 현명한 방법입니다.
iv. 적용이슈
- 혼동될 여지가 없고 트레이드 오프를 고려해 선택한 것이라면 그대로 둡니다.
- 다형성을 위한 상속 관계가 필요 없다면 Replace with Delegation을 합니다. 상속은 깨지기 쉬운 기반 클래스 등을 지니고 있으므로 IS-A관계가 성립되지 않습니다. LSP를 지키기 어렵다면 상속대신 합성(composition)을 사용하는 것이 좋습니다.
- 상속 구조가 필요 하다면 Extract Subclass, Push Down Field, Push Down Method 등의 리팩토링 기법을 이용하여 LSP를 준수하는 상속 계층 구조를 구성 합니다.
- IS-A관계가 성립한다고 프로그램에서 까지 그런것은 아닙니다. 이들간의 관계 맺음은 이들의 역할과 이들 사이에 공유하는 연산이 있는지, 그리고 이들 연산이 어떻게 다른지 등을 종합적으로 검토 해 봐야 합니다.
- Design by Contract(“서브 클래스에서는 기반 클래스의 사전 조건과 같거나 더 약한 수준에서 사전 조건을 대체할 수 있고, 기반 클래스의 사후 조건과 같거나 더 강한 수준에서 사후 조건을 대체할 수 있다.”)적용: 기반 클래스를 서브 클래스로 치환 가능하게 하려면 받아들이는 선 조건에서 서브 클래스의 제약사항이 기반 클래스의 제약 사항보다 느슨하거나 같아야 합니다. 만약 제약조건이 더 강하다면 기반 클래스에서 실행되던 것이 서브 클래스의 강 조건으로 인해 실행되지 않을 수도 있기 때문입니다. 반면 서브 클래스의 후 조건은 같거나 더 강해야 하는데, 약하다면 기반 클래스의 후 조건이 통과시키지 않는 상태를 통과시킬 수도 있기 때문입니다.
D. ISP (인터페이스 분리의 원칙: Interface Segregation Principle)
CLIENTS SHOULD NOT BE FORCED TO DEPEND UPON INTERFACES
THAT THEY DO NOT USE.
i. 정의
ISP원리는 한 클래스는 자신이 사용하지 않는 인터페이스는 구현하지 말아야 한다는 원리입니다. 즉 어떤 클래스가 다른 클래스에 종속될 때에는 가능한 최소한의 인터페이스만을 사용해야 합니다. ISP를 ‘하나의 일반적인 인터페이스보다는, 여러 개의 구체적인 인터페이스가 낫다’라고 정의할 수 도 있습니다. 만약 어떤 클래스를 이용하는 클라이언트가 여러 개고 이들이 해당 클래스의 특정 부분집합만을 이용한다면, 이들을 따로 인터페이스로 빼내어 클라이언트가 기대하는 메시지만을 전달할 수 있도록 합니다. SRP가 클래스의 단일책임을 강조한다면 ISP는 인터페이스의 단일책임을 강조합니다. 하지만 ISP는 어떤 클래스 혹은 인터페이스가 여러 책임 혹은 역할을 갖는 것을 인정합니다. 이러한 경우 ISP가 사용되는데 SRP가 클래스 분리를 통해 변화에의 적응성을 획득하는 반면, ISP에서는 인터페이스 분리를 통해 같은 목표에 도달 합니다.
ii. 적용방법
- 클래스 인터페이스를 통한 분리
- 클래스의 상속을 이용하여 인터페이스를 나눌 수 있습니다.
이와 같은 구조는 클라이언트에게 변화를 주지 않을 뿐 아니라 인터페이스를 분리하는 효과를 갖습니다. 하지만 거의 모든 객체지향 언어에서는 상속을 이용한 확장은 상속받는 클래스의 성격을 디자인 시점에 규정해 버립니다. 따라서 인터페이스를 상속받는 순간 인터페이스에 예속되어 제공하는 서비스의 성격이 제한 됩니다.
- 객체 인터페이스를 통한 분리
- 위임(Delegation)을 이용하여 인터페이스를 나눌 수 있습니다.
위임이란, 특정 일의 책임을 다른 클래스나 메소드에 맡기는 것입니다. 만약 다른 클래스의 기능을 사용해야 하지만 그 기능을 변경하고 싶지 않다면, 상속 대신 위임을 사용 합니다.
iii. 적용사례
Java Swing의 JTable
JTable 클래스에는 굉장히 많은 메소드들이 있습니다. 컬럼을 추가하고 셀 에디터 리스너를 부착하는 등 여러 역할이 하나의 클래스 안에 혼재되어 있지만 JTable의 입장에서 본다면 모두 제공해야 하는 역할입니다. JTable은 ISP가 제안하는 방식으로 모든 인터페이스 분리를 통해 특정 역할만을 이용할 수 있도록 해줍니다. 즉, Accessible, CellEditorListener, ListSelectionListener, Scrollable, TableColumnModelListener, TableMoldelListener 등 여러 인터페이스 구현을 통해 서비스를 제공합니다. JTable은 자신을 이용하여 테이블을 만드는 객체, 즉 모든 서비스를 필요로 하는 객체에게는 기능 전부를 노출하지만, 이벤트 처리와 관련해서는 여러 리스너 인터페이스를 통해 해당 기능만 노출합니다.
import javax.swing.event.*;
import javax.swing.table.TableModel;
public class SimpleTableDemo ... implements TableModelListener {
...
public SimpleTableDemo() {
...
table.getModel().addTableModelListener(this);
...
}
//인터페이스를 통해 노출할 기능을 구현합니다.
public void tableChanged(TableModelEvent e) {
int row = e.getFirstRow();
int column = e.getColumn();
TableModel model = (TableModel)e.getSource();
String columnName = model.getColumnName(column);
Object data = model.getValueAt(row, column);
...// Do something with the data...
}
...
}
iv. 적용이슈
- 기 구현된 클라이언트에 변경을 주지 말아야 합니다.
- 두 개 이상의 인터페이스가 공유하는 부분의 재사용을 극대화 합니다.
- 서로 다른 성격의 인터페이스를 명백히 분리 합니다.
E. DIP (의존성역전의 원칙: Dependency Inversion Principle)
A. HIGH LEVEL MODULES SHOULD NOT DEPEND UPON LOW LEVEL MODULES. BOTH SHOULD DEPEND UPON ABSTRACTIONS.
B. ABSTRACTIONS SHOULD NOT DEPEND UPON DETAILS. DETAILS SHOULD DEPEND UPON ABSTRACTIONS.
i. 정의
의존 관계의 역전 Dependency Inversion 이란 구조적 디자인에서 발생하던 하위 레벨 모듈의 변경이 상위 레벨 모듈의 변경을 요구하는 위계관계를 끊는 의미의역전입니다. 실제 사용 관계는 바뀌지 않으며, 추상을 매개로 메시지를 주고 받음으로써 관계를 최대한 느슨하게 만드는 원칙입니다.
DIP의 키워드는 ‘IOC’, ‘훅 메소드*(슈퍼클래스에서 디폴트 기능을 정의해두거나 비워뒀다가 서브클래스에서 선택적으로 오버라이드할 수 있도록 만들어둔 메소드를 훅(hook) 메소드라고 합니다. 서브클래스에서는 추상 메소드를 구현하거나, 훅 메소드를 오버라이드하는 방법을 이용해 기능의 일부를 확장합니다.)*’’, ‘확장성’입니다. 이 세 가지 요소가 조합되어 복잡한 컴포넌트들의 관계를 단순화하고 컴포넌트 간의 커뮤니케이션을 효율적이게 합니다.
이를 위해 Callee 컴포넌트(예를 들어 프레임워크)는 Caller 컴포넌트들이 등록할 수 있는 인터페이스를 제공 합니다. 따라서 자연스럽게 Callee는 Caller들의 컨테이너 역할이 됩니다.(JMS의 Topic 제공자, 스윙 컴포넌트, 배우 섭외 담당자들은 등록자들을 관리합니다). Callee 컴포넌트는 Caller 컴포넌트가 확장(구현)할, 그리고 IOC를 위한 훅 메소드 인터페이스를 정의 합니다. Caller 컴포넌트는 정의된 훅 메소드를 구현합니다. 이로써 DIP를 위한 준비가 완료되고 이 상태에서 다음과 같은 시나리오가 전개됩니다. Caller는 Callee에 자신을 등록합니다. Callee는 Caller에게 정보를 제공할 적당한 시점에 Caller의 훅 메소드를 호출합니다. 바로 이 시점은 Caller와 Callee의 호출관계가 역전되는 IOC 시점이 됩니다. DIP는 비동기적으로 커뮤니케이션이 이루어져도 될 (혹은, 이뤄져야 할) 경우, 컴포넌트 간의 커뮤니케이션이 복잡할 경우, 컴포넌트 간의 커뮤니케이션이 비효율적일 경우(빈번하게 확인해야 하는)에 사용됩니다.
DIP는 복잡하고 지난한 컴포넌트간의 커뮤니케이션 관계를 단순화하기 위한 원칙입니다. 실 세계에서도 헐리우드 원칙에서와 같이 귀찮도록 자주 질문과 요청을 하는 동료에게도 써먹어 볼만한 원칙입니다.
ii. 적용방법
1. Layering
Grady Booch(Object Solutions, Addison Wesley, 1996, p54)는 “…all well structured object-oriented architectures have clearly-defined layers, with each layer providing some coherent set of services though a well-defined and controlled interface.”라고 하였습니다. 즉, 잘 구조화된 객체지향 아키텍처들은 각 레이어마다 잘 정의되고 통제되는 인터페이스를 통한 긴밀한 서비스들의 집합을 제공하는 레이어들로 구성되어 있습니다. 이것은 단순히 레이어를 통한 구조화만을 뜻하는 것이 아니라 Transitive Dependency가 발생했을 때 상위 레벨의 레이어가 하위 레벨의 레이어를 바로 의존하게 하는 것이 아니라 이 둘 사이에 존재하는 추상레벨을 통해 의존해야 할 것을 말하고 있습니다. 이를 통해서 상위레벨의 모듈은 하위레벨의 모듈로의 의존성에서 벗어나 그 자체로 재사용 되고 확장성도 보장 받을 수 있습니다. 이를 도식화하면 다음과 같습니다.
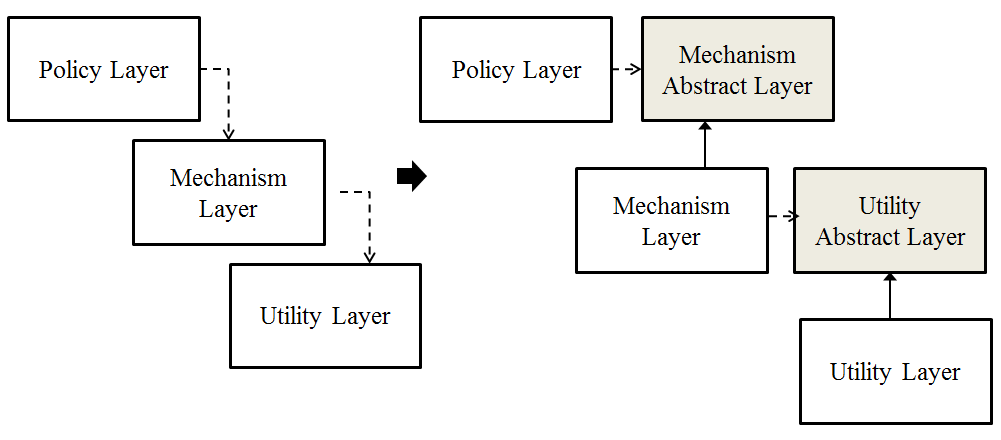
iii. 적용사례
1. 통신 프로그래밍 모델
일반적으로 소켓 프로그램은 클라이언트가 서버에게 요청을 send()하고 서버로부터 결과를 recv()하므로 서버의 서비스를 이용합니다. 멀티스레드 프로그래밍에서 이 send() & recv()를 하게 되면 recv() 함수는 블럭되기 때문에 recv()하는 동안 스레드는 서버의 응답이 오기까지 대기합니다. 따라서 서버로부터의 응답을 받기 위해 대기하는 동안 recv()를 호출한 스레드는 다른 작업을 할 수 없기 때문에 스레드 자원이 낭비됩니다.
이 방식의 대안으로 제시되는 모델이 폴링(polling) 모델입니다. 클라이언트 스레드는 서버에게 메시지를 보내고 recv()를 전담하는 스레드에게 recv()를 맡깁니다. 그리고 이 스레드들은 다른 작업을 실행하면서 계속 일합니다. 서버로부터 응답을 확인하고 싶은 시점에서 접수된 서버의 메시지를 가져옵니다. 따라서 클라이언트 스레드는 다른 일을 할 수 있는 기회비용을 얻습니다. 하지만 폴링 모델에서 어느 순간 클라이언트 스레드는 서버의 응답을 확인해야 합니다. 단지 자신이 원하는 시점에 서버의 응답을 확인하는 장점과 응답을 기다리는 시간에 다른 작업을 할 수 있는 기회를 확보할 뿐이지요. 이 모델까지는 확실히 모든 통제가 클라이언트 스레드의 스케쥴 안에 있습니다. 그리고 동기적으로 (자신이 원하는 시점에) 서버의 응답을 확인할 수 있습니다.
하지만 만약 서버의 응답이 예상보다 지연될 경우 클라이언트 스레드는 서버의 응답이 올 때까지 여러 번 응답 큐를 확인하는 비용이 따릅니다. 또한 서버의 응답을 확인하는 시점이 동기적이지 않아도 될 경우 더더욱 이 확인 작업은 지난해 집니다. 즉, 서버의 응답에 대한 처리가 비 동기적이어도 될 때, 그리고 클라이언트 스레드가 서버의 응답 확인하는 시도가 여러 번 발생할 때 폴링 모델도 오버헤드가 발생합니다.
이 때가 DIP를 적용하기 적당한 시점이 되는데 클라이언트 스레드는 메시지를 send()한 후에 recv()하는 대신 서버의 응답을 처리하는 훅 메소드를 등록합니다. - 구조적 프로그램에서는 함수 포인터를 등록하지만 객체지향 세계에서의 트랜드는 커멘드 오브젝트를 등록합니다(GoF의 커멘드 패턴 참조). recv()를 담당하는 스레드는 서버로부터 응답을 접수하면 대응하는 훅 메소드를 찾아 훅 메소드를 실행합니다. 즉 recv() 스레드는 서버의 응답 접수와 훅 메소드 실행을 담당합니다. 이 모델은 비 동기 소켓 모델로서 DIP의 원칙을 그대로 따르고 있습니다. - 클라이언트 스레드들은 헐리우드 원칙에서의 배우로 receive 스레드는 영화기획사 담당자로 생각해 보세요. 비동기 모델에서 얻을 수 있는 장점은 첫째, 클라이언트 스레드의 잦은 응답 확인을 제거할 수 있습니다. 둘째, 클라이언트 스레드는 응답을 확인하는 작업에서 자유로워지므로 다른 작업을 할 수 있는 기회비용을 확보할 수 있습니다. 물론 이 과정은 비동기적으로 이루어져도 괜찮은 상황에 한합니다. 무엇보다 중요한 것은 이런 구조의 바탕에는 통제권이 클라이언트 스레드에서 커멘드 오브젝트로 역전되는 IOC가 전제됩니다. DIP를 적용할 때 기대할 수 있는 장점은 상술한 두 가지 장점을 그대로 확보하는데 있는데, 바로 퍼포먼스를 높이고 요청에 대한 응답으로부터 관심을 제거하여 클라이언트의 역할을 단순화하는 데 있습니다.
2. 이벤트 드리븐, 콜백 그리고 JMS 모델
자바 API는 언제나 소프트웨어 설계의 좋은 모델이 됩니다. 또한 자바 스윙의 이벤트 모델에도 DIP의 원리가 녹아 있습니다. 자바 스윙 컴포넌트는 이벤트를 처리할 java.awt.event.ActionListener를 등록(addActionListener())합니다. 이 스윙 컴포넌트에 이벤트가 발생하면 등록된 ActionListener의 훅 메소드인 actionPerformed()를 후킹합니다. 스윙 컴포넌트에는 복수 개의 이벤트가 발생할 수 있기 때문에 복수 개의 ActionListener를 등록할 수 있습니다. 이와 유사한 구조로 더 일반화된 Observer & Observable 인터페이스(자바에서 지원하는 내장 옵저버 패턴)도 있습니다. 더 나아가서 분산 시스템에서도 똑같은 구조가 적용됩니다.
서버와 클라이언트간의 통신에 있어서 클라이언트는 서버에 자신의 원격 객체 레퍼런스를 등록합니다. 서버는 자신의 작업을 진행하면서 원격 객체 레퍼런스를 통해 그때그때 필요한 정보를 클라이언트에게 제공합니다. 이 구조를 위해서 클라이언트의 콜백(callback) 메소드가 미리 정의되어 있어야 합니다. 콜백 메소드는 서버가 비동기적으로 클라이언트에게 정보를 전달하는 훅 메소드가 됩니다. 따라서 콜백의 구조는 원격지에서 훅킹이 제공되는 형태를 갖습니다.
이와 같은 구조는 비 동기적인 분산 훅킹(콜백)구조를 형성할 때 사용됩니다. 가령 서버에게 장시간의 작업들을 할당하고 클라이언트가 각 작업의 결과에 대한 중간보고를 비동기적으로 받고 싶을 때 유용합니다. 클라이언트의 호출이 비 동기적이기 때문에 서버의 작업을 할당한 다음 클라이언트는 다시 자신의 작업이 진행됩니다. 따라서 앞서 예시한 소켓의 비 동기 모델에서 recv() 스레드가 서버의 역할로 전이된 형태를 갖습니다. JMS의 토픽 모델은 좀 더 다양한 구조를 갖습니다. - 이 모델은 전통적인 MOM*(메시지 지향 미들웨어: Message-Oriented Middleware- 분산 응용 프로그램 간에 메시지를 전송 및 수신하여 데이터 통신과 교환을 가능하게 합니다.)* 아키텍처에서 Publish/Subscribe 메시징 모델로 알려져 있습니다.
이 모델은 멀티캐스팅 같은 그룹 메시징을 제공할 때 유용한데, 가령 주식정보 시스템을 예로 들었을 때 주식정보 제공자는 가입한 모든 클라이언트에게 현재 증시정보를 멀티캐스팅 합니다. 이 때 주식정보 제공자는 Publisher가 되고 클라이언트 프로그램은 Subscriber가 됩니다. 참고로 이 모델의 장점은 클라이언트/서버에서 메시지 기반으로 패러다임이 바뀐다는 것입니다.
기존의 클라이언트/서버 모델의 경우 서버는 클라이언트들을 상대합니다. 따라서 클라이언트의 위치 정보와 인터페이스 등을 알아야 했습니다. Publish/Subscribe 모델에서는 이 클라이언트와 서버 간의 상호의존도가 제거되며 이제부터 서버는 각종 클라이언트들에게 메시지를 보내는 것이 아니라 그냥 ‘주식정보’라는 메시지를 보내면 될 뿐입니다. 즉, 어떤 클라이언트들이 얼마나 접속되어있는지, 각 클라이언트들의 위치와 인터페이스는 어떤지 등의 여부와 같은 클라이언트 정보는 관심 대상에서 제외되고(주식정보라는) 메시지에 관심을 집중하게 됩니다. 이 패러다임은 클라이언트가 몇 개 접속되어 있는지 혹은 아예 없든지, 클라이언트의 상태나 위치가 어떤지에 관심 없이 그룹 메시징 제공자에게 메시지를 보내기만 하면 될 뿐입니다. 이 모델에서 Subscriber들은 Topic 제공자에게 자신을 등록합니다. Publisher가 Topic 제공자에게 메시지를 전송하면 JMS Topic 제공자는 등록된 Subscriber들에게 메시지를 멀티캐스팅 합니다. 이 때 메시지 멀티캐스팅을 하기 위해 등록된 각 Subscriber들의 onMessage()를 호출하게 됩니다.
2. 마치며
객체지향 원칙과 사고방식이 중요하다는 건 분명한 사실이나, 이것 보다 더 우선해야 할 것이 고객의 요구사항대로 동작해야 한다는 것입니다. 아무리 아름답게 디자인 되고 멋진 기능을 가진 자동차라도 움직이지 않거나 물이 샌다면 잘 만들어진 자동차가 아니듯, 아무리 객체지향 원칙을 적용하고 멋진 패턴을 사용하여 확장성이 뛰어나고 유연하게 설계가 되었다 하더라도 오동작하거나 동작하지 않는 프로그램이라면 이후의 상황은 굳이 말하지 않아도 짐작하시리라 생각됩니다. 오늘 알아본 객체지향 원칙은 반드시 “고객의 만족”을 충족한다는 전재하에 적용되어야 합니다.
- 여러분의 소프트웨어가 고객이 원하는 기능을 하도록 하세요.
- 객체지향 기본원리를 적용해서 소프트웨어를 유연하게 하세요.
- 유지보수와 재사용이 쉬운 디자인을 위해 노력하세요.
(헤드퍼스트 OOA&D 中)
참고자료
- http://www.zdnet.co.kr/news/news_view.asp?artice_id=00000039135552&type=det
- http://www.zdnet.co.kr/news/news_view.asp?artice_id=00000039137043&type=det
- http://www.zdnet.co.kr/news/news_view.asp?artice_id=00000039134727&type=det
- http://www.zdnet.co.kr/news/news_view.asp?artice_id=00000039139151&type=det
- http://www.objectmentor.com/resources/articles/ocp.pdf
- http://www.objectmentor.com/resources/articles/srp.pdf
- http://www.objectmentor.com/resources/articles/lsp.pdf
- http://www.objectmentor.com/resources/articles/isp.pdf
- http://www.objectmentor.com/resources/articles/dip.pdf
- http://vandbt.tistory.com/41
- Object-Oriented Analysis & Design 브렛 맥래프린, 게리폴리스, 데이빗 웨스트 저/ 신광연, 박종걸 역, O’REILLY
- Java 프로그래머를 위한 UML 실전에서는 이것만 쓴다! 로버트 C.마틴 저 / 이용원, 정지호 역, 인사이트
SOLID: 컴퓨터 프로그래밍에서 SOLID란 로버트 마틴이 2000년대 초반에 명명한 객체 지향 프로그래밍 및 설계의 다섯 가지 기본 원칙을 마이클 페더스가 두문자어 기억술로 소개한 것입니다. 프로그래머가 시간이 지나도 유지 보수와 확장이 쉬운 시스템을 만들고자 할 때 이 원칙들을 함께 적용할 수 있습니다. SOLID 원칙들은 소프트웨어 작업에서 프로그래머가 소스 코드가 읽기 쉽고 확장하기 쉽게 될 때까지 소프트웨어 소스 코드를 리팩토링하여 코드 냄새를 제거하기 위해 적용할 수 있는 지침입니다. 이 원칙들은 애자일 소프트웨어 개발과 적응적 소프트웨어 개발의 전반적 전략의 일부입니다.

