대부분의 기업형 애플리케이션은 중앙의 서버에서 동작합니다. 이러한 서버는 Web을 위한 HTTP 서버 또는 소켓 통신을 위한 네트워크 서버 등이 있습니다. 서버는 중앙집중형태로 클라이언트의 요청을 받으므로 병목현상이 발생하기 쉬우며 처리 성능에 항상 주목해야 합니다.
클라이언트의 요청이 많은 경우 서버는 병목 구간이 발생합니다. 이러한 병목구간을 분석해 보면 대부분 프로그램 로직보다는 입출력(IO)에서 발생합니다. IO에서 소요되는 비용은 생각보다 많이 나옵니다. 아래의 통계자료를 보면 주로 Disk 나 Network Access 시 비용이 가장 많이 나오는 것을 확인할 수 있습니다.

이와같이 서버에서 IO를 처리하다가 지연이 발생하면 다른 요청들은 처리되지 못하고 계속 대기하는 현상이 발생합니다. 그래서 대부분의 기업형 서버 플랫폼들은 이 문제를 해결하기 위하여 사용자의 요청을 쓰레드로 처리하고 있습니다.
Multi-Thread 의 한계
Multi-Thread 방식은 서버의 요청 처리를 쓰레드에서 처리하도록 하여 병렬처리를 가능하도록 하는 방식입니다. 쓰레드는 서버 CPU 자원을 시분할 형태로 나누어 가짐으로써 독립실행이 가능하며 다른 요청을 동시에 받을 수 있게 합니다.
이러한 방식은 IO Blocking을 해결하는 이상적인 모델로 보일 수 있습니다. 그러나 몇가지 한계도 존재합니다.
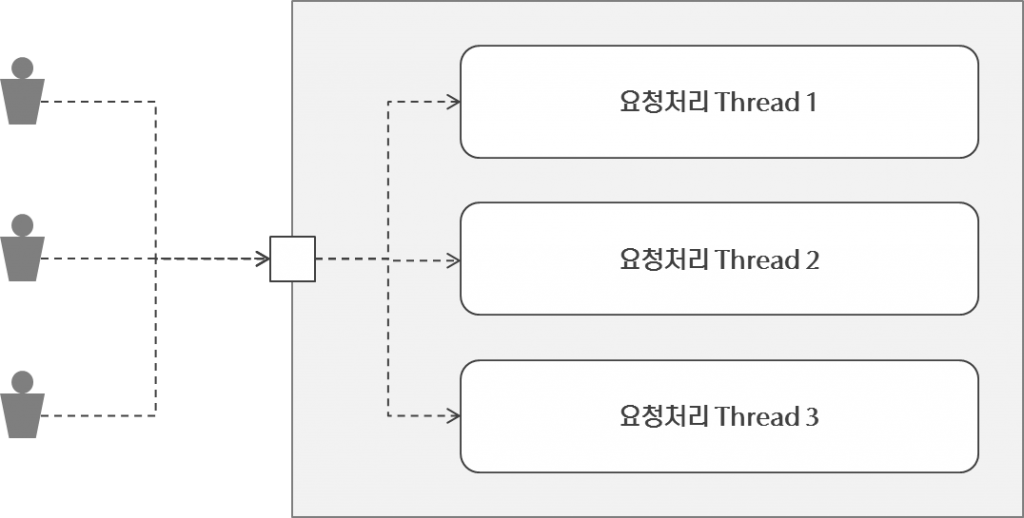
Multi-Thread 기반의 서버는 일반적으로 클라이언트의 요청마다 Thread를 발생시킵니다. 이 말은 동시 접속자 수가 많을 수록 Thread가 많이 발생한다는 의미이며 그만큼 메모리 자원도 많이 소모한다는 의미입니다. 그러나 서버의 자원은 제한되어 있으므로 일정 수 이상의 Thread는 발생시킬 수 없습니다.
Multi-Thread 는 이런 근본적인 문제를 안고 있기 때문에 현장에서는 서버를 업그레이드 하거나 Load-Balancing 등으로 분산처리 하는 것입니다.
한편 Multi-Thread 방식은 각 Thread 간의 공유자원 접근시 신중해야 합니다. 각 Thread는 독립적인 시점에서 동작하므로 공유자원에 대한 동기화 없이 접근하면 예기치 않은 결과가 나올 수 있습니다.
병렬처리의 대안: 비동기 처리
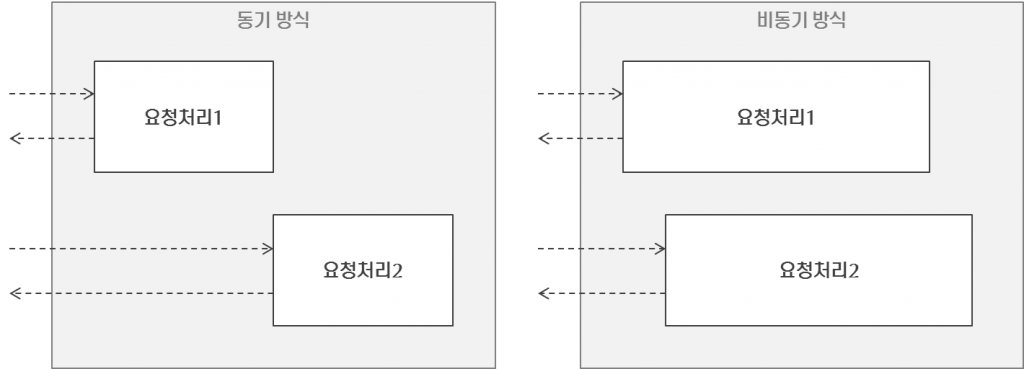
동기방식의 처리는 하나의 요청이 처리되는 동안 다른 요청이 처리되지 못하며 요청이 완료되어야만 다음 처리가 가능한 방식입니다. 동기 방식은 IO 처리를 Blocking 하는데 지금까지는 이 문제를 Thread로 처리했습니다.
이 문제를 비동기 방식으로 처리할 수도 있습니다. 비동기 방식은 하나의 요청 처리가 완료되기 전에 제어권을 다음 요청으로 넘깁니다. 따라서 IO 처리인 경우 Blocking 되지 않으며 다음 요청을 처리할 수 있는 것입니다.
Node.js 는 바로 이와같은 방식으로 병렬처리를 합니다.
Node.js 의 비동기 처리
Node.js 는 비동기 IO를 지원하며 Single-Thread 기반으로 동작하는 서버입니다. Node 서버는 비동기 방식으로 요청을 처리하므로 요청을 처리하면서 다음 요청을 받을 수 있습니다. 또한 병렬처리를 Thread 로 처리하지 않으므로 Multi-Thread가 갖는 근원적인 문제에서 자유롭습니다.
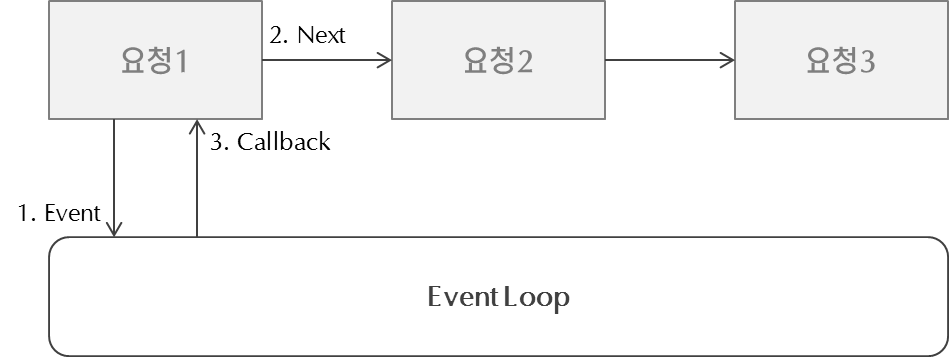
Node.js 의 비동기 처리는 이벤트 방식으로 풀어냅니다. 클라이언트의 요청을 비동기로 처리하기 위하여 이벤트가 발생하며 서버 내부에 메시지 형태로 전달됩니다. 서버 내부에서는 이 메시지를 Event Loop가 처리합니다. Event Loop가 처리하는 동안 제어권은 다음 요청으로 넘어가고 처리가 완료되면 Callback을 호출하여 처리완료를 호출측에 알려줍니다.
Event Loop는 요청을 처리하기 위하여 내부적으로 약간의 Thread와 프로세스를 사용합니다. 이는 Non-Blocking IO 또는 내부 처리를 위한 목적으로만 사용되지 요청 처리 자체를 Thread로 하지는 않습니다. 따라서 Node 서버는 Multi-Thread 방식의 서버에 비하여 Thread 수와 오버헤드가 훨씬 적습니다.
이벤트를 처리하는 Event Loop는 Single-Thread 로 이루어져 있습니다. 즉 요청 처리는 하나의 Thread 안에서 처리된다는 의미입니다. 그래서 이벤트 호출 측에는 비동기로 처리되지만 처리작업 자체가 오래 걸린다면 전체 서버 처리에 영향을 줍니다. 이는 Node.js 의 치명적인 약점이라고 볼 수 있습니다.
Node.js 의 올바른 사용
Node.js 는 Google Chrome V8 엔진 기반으로 동작하며 내부의 Event Loop는 Single-Thread 기반에서 비동기 메시지를 처리합니다. 이러한 Event Loop는 고성능의 병렬처리를 보장하도록 설계되어 있습니다. 따라서 이벤트에 의해 처리해야 할 단위 작업이 아주 짧은 시간 안에 처리된다면 Node.js의 고성능의 장점을 극대화 할 수 있습니다.
만일 처리 작업이 CPU를 많이 소모한다든지 대용량 파일을 처리하는 작업이라면 Node.js 는 독약과도 같습니다. 그러나 IO 작업이 별로 없는 애플리케이션이나 단위작업이 짧은 메시징 애플리케이션의 경우에는 Node.js는 고성능을 보장해 줍니다.
한편 Node 애플리케이션 개발자가 처리 로직을 비동기로 하지 않고 동기방식으로 구성한다면 Node를 잘못 활용하는 결과를 낳을 수 있습니다. 따라서 Node 애플리케이션은 가능한 한 전부 비동기로 처리해야 하며 Node 개발자는 비동기 프로그래밍 방식에 익숙해져야 할 필요가 있습니다.
비동기 프로그래밍 기본
Node를 접해보지 않은 대부분의 개발자들은 비동기 보다는 동기방식에 익숙해져 있습니다. Node 애플리케이션을 개발하면서 동기방식 코드의 늪에 빠지지 않기 위해서는 지금까지 알고 있던 프로그래밍 패턴을 바꿔야 합니다. 그리고 코드를 구현할 때 생각 자체를 비동기 방식으로 바꿔야 합니다. 처음에는 쉽진 않겠지만 습관을 바꾸기 위해서는 꾸준히 연습해야 합니다.
var fs = require('fs');
// non-blocking code
fs.readdir('.', function (err, filenames){
// callback
});
console.log('can process next job...');
비동기 프로그래밍의 기본은 비동기 API를 사용하여 비동기 이벤트를 발생시키고 완료여부를 알 수 있도록 Callback을 정의하는 것입니다. 예제 코드 내의 Callback 블럭은 이벤트 처리가 완료되면 호출됩니다. 코드라인의 진행은 이벤트 발생 후에도 바로 진행이 되므로 맨 마지막 라인의 로그는 즉시 출력됩니다.
동기 방식에서 비동기로 전환하는 방법
아래의 두가지 코드 중 첫번째는 동기방식이며 두번째는 같은 내용이지만 비동기로 구현한 예제입니다. 아래의 예제에서 동기방식의 코드를 어떻게 비동기로 전환하는지 알아보겠습니다.
var fs = require('fs');
var filenames = fs.readdirSync('.');
var i;
for (i = 0; i < filenames.length; i++) {
console.log(filenames[i]);
}
console.log('ready');
console.log('can process next job...');
var fs = require('fs');
fs.readdir('.', function (err, filenames){
var i;
for (i = 0; i < filenames.length; i++) {
console.log(filenames[i]);
}
console.log('ready');
});
console.log('can process next job...');
첫번째 코드에서 우리는 현재 디렉토리에 존재하는 파일 목록 출력 로직을 동기 방식으로 구현했습니다. Node에서 제공하는 'File System' API를 사용하였으며 동기방식의 API를 사용하였습니다. 동기방식의 코드 구현은 간단합니다. 우리 평소에 생각했던 방법으로 구현하면 됩니다.
이러한 동기방식의 코드를 비동기로 전환하는 첫번째 방법은 동기방식 API에 대응하는 비동기 API로 교체하는 것입니다. 두번째는 동기 방식에서 동기API 호출 이후 처리로직을 그대로 Callback 함수로 옮기는 것입니다.
비동기 방식에서 Callback은 주로 함수로 표현됩니다. 자바스크립트에서 함수는 First-Class Function 이므로 변수에 할당할 수 있고 다른 함수의 파라미터로 전달할 수도 있는 것입니다. 이러한 Callback 함수는 비동기 API의 마지막 인자로 전달됩니다. 그리고 전달된 Callback 함수는 디렉토리 읽는 작업이 완료된 후 호출됩니다. 우리는 이 Callback 함수에서 파일목록을 출력하는 로직을 구성하였습니다.
특히 주의깊게 봐야되는 부분은 Callback 함수 내의 'ready' 메시지보다 Callback 밖의 'can process next job...' 메시지가 먼저 출력된다는 사실입니다. 이는 File System 의 비동기 API를 사용했기 때문입니다.
비동기 프로그램에서 순차처리
동기 프로그램에서 순서가 요구되는 로직 처리는 쉽습니다. 그냥 순서에 따라 로직을 기술해 나가기만 하면 됩니다. 그러나 비동기 방식에서는 각각의 처리로직이 병렬로 수행되므로 이 처리로직이 언제 시작되며 또한 언제 종료되는지 알수가 없습니다.
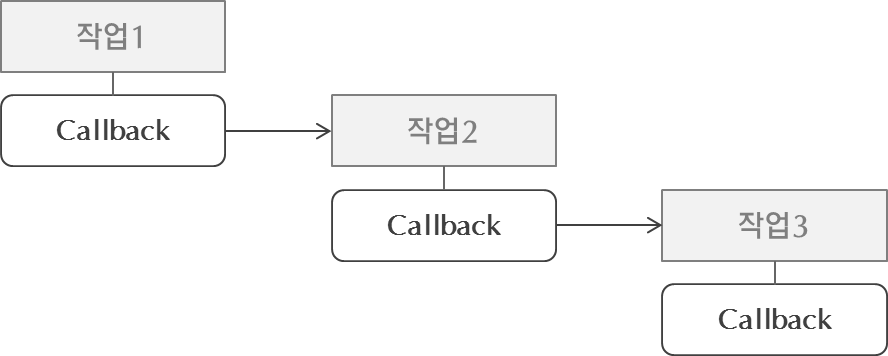
우리는 앞의 예제에서 비동기 처리시 항상 Callback 을 사용한다는 사실을 알 수 있었습니다. Callback은 비동기 처리가 완료되면 호출되므로 우리는 이 Callback을 이용하여 순차처리를 할 수 있습니다.
var fs = require('fs');
var oldFilename = './processId.txt';
var newFilename = './processIdOld.txt';
fs.chmodSync(oldFilename, 777);
console.log('complete chmod.');
fs.renameSync(oldFilename, newFilename);
console.log('complete rename.');
var isSymLink = fs.lstatSync(newFilename).isSymbolicLink();
console.log('complete symbolic check.');
var fs = require('fs');
var oldFilename = './processId.txt';
var newFilename = './processIdOld.txt';
fs.chmod(oldFilename, 777, function (err) {
console.log('complete chmod.');
fs.rename(oldFilename, newFilename, function (err) {
console.log('complete rename.');
fs.lstat(newFilename, function (err, stats) {
var isSymLink = stats.isSymbolicLink();
console.log('complete symbolic check.');
});
});
});
동기방식의 순차처리코드는 위의 예제와 같이 파일의 소유권을 바꾸고, 파일명을 변경하며, 심볼릭 링크를 만드는 작업을 순차적으로 진행합니다. 물론 모든 API는 동기API를 사용합니다.
비동기 방식에서 순차처리는 중첩된 Callback을 이용하여 순서가 보장되게끔 합니다. Callback은 항상 처리 완료 후에 호출되므로 Callback을 중첩시키면 순서가 뒤바뀔 일이 없습니다.
그러나 위의 예제처럼 중첩 Callback을 사용하면 그 코드의 Depth 가 너무 깊어진다는 단점이 있습니다. 위의 예제는 중첩을 3번 사용하였지만 중첩 Callback을 너무 과도하게 사용하면 코드의 가독성이 급격하게 떨어집니다.
이와같은 문제를 해결해 주는 프레임워크가 몇가지 있습니다. 여기서는 'async' 라는 모듈을 사용하였습니다.
var fs = require('fs');
var async = require('async');
var oldFilename = './processId.txt';
var newFilename = './processIdOld.txt';
async.waterfall([
function (cb) {
fs.chmod(oldFilename, 777, function (err){
console.log('complete chmod.');
cb(null);
});
},
function (cb) {
fs.rename(oldFilename, newFilename, function (err) {
console.log('complete rename.');
cb(null);
});
},
function (cb) {
fs.lstat(newFilename, function (err, stats) {
var isSymLink = stats.isSymbolicLink();
console.log('complete symbolic check.');
});
}
]);
'async' 모듈을 사용하려면 Node Packaged Modules(NPM)로 모듈을 설치해야 합니다. 설치방법은 'npm install async' 으로 설치하면 됩니다. async 모듈의 waterfall API를 사용하면 Callback의 중첩을 줄이면서 로직의 순서를 보장합니다.
Node.js 의 병렬처리
비동기 방식이지만 Event Loop에서 처리되는 작업이 긴 시간을 요구하는 경우 전체 서버의 성능이 저하됩니다. 이 점은 앞에서 이미 말씀드렸습니다. 이런 경우 전달할 이벤트를 가능한한 잘게 쪼개어 병렬로 처리될 수 있게 유도해야 합니다.
var fs = require('fs');
function calculateBytes() {
var totalBytes = 0,
i,
filenames,
stats;
filenames = fs.readdirSync('.');
for (i = 0; i < filenames.length; i++) {
stats = fs.statSync('./' + filenames[i]);
totalBytes += stats.size;
}
console.log(totalBytes);
}
calculateBytes();
var fs = require('fs');
function calculateBytes() {
fs.readdir('.', function (err, filenames) {
var count = filenames.length;
var totalBytes = 0;
var i;
for (i = 0; i < filenames.length; i++) {
fs.stat('./' + filenames[i], function (err, stats) {
totalBytes += stats.size;
count--;
if (count === 0) {
console.log(totalBytes);
}
});
}
});
}
calculateBytes();
현재 디렉토리의 파일목록을 구한 후 전체 파일사이즈를 계산하는 예제입니다. 동기방식은 우리가 흔히 사용하는 방법이며 아주 쉽습니다.
비동기 방식에서 각 파일의 사이즈를 구하여 이를 합치는 과정은 상당히 긴 시간을 요구하는 작업입니다. 따라서 이러한 작업을 작은 단위로 나누어서 병렬처리하였습니다. 즉 파일 목록에서 각 파일마다 비동기 이벤트를 전달하는 방식입니다. 이렇게 되면 단위작업이 많아지게 되므로 전체 서버에서의 부담은 적어집니다.
여기서 'fs.stat()' API에 전달되는 Callback 함수는 파일 사이즈의 총 합을 저장하기 위하여 외부 함수의 변수에 접근합니다. 이는 Callback 함수가 Closure 이기 때문에 가능합니다. 참고로 Closure 는 자신의 Scope 뿐만 아니라 외부 함수의 Scope도 가집니다.
우리가 특히 눈여겨 봐야 될 부분은 'count' 변수입니다. 일반적으로 하나의 작업을 병렬로 분산처리 할 경우 언제 전체 작업이 완료되는지 알 수 없습니다. 위의 예제는 이 문제를 해결하기 위하여 Callback이 전달된 횟수만큼 count에 저장하고 각 작업이 완료될 때 마다 count를 하나씩 감소시킵니다. 그래서 count가 0이 되면 모든 작업이 완료되었다는 것을 의미합니다.
따라서 일반적으로 병렬처리시에는 count를 이용한 패턴을 자주 사용합니다.
코드 재사용
비동기 메시지 전달시 사용되는 Callback 함수는 동일한 패턴이 있을 경우 재사용될 수 있습니다.
var fs = require('fs');
var path1 = './';
var path2 = '.././';
var countCallback;
function countFiles(path, callback) {
fs.readdir(path, function (err, filenames) {
callback(err, path, filenames.length);
});
}
countCallback = function (err, path, count) {
console.log(count + ' files in ' + path);
};
countFiles(path1, countCallback);
countFiles(path2, countCallback);
일반 함수가 변수에 할당되면 필요할 때마다 다른 함수의 인자로 넘어갈 수 있습니다. 'countFile()' 함수는 함수를 인자로 전달받아 이를 Callback 함수로 전환시킵니다. 즉 일반함수를 Callback 함수로 Wrapping 하면 Callback 함수가 되는 것입니다. 이러한 형태로 함수 코드를 재사용할 수 있습니다.
Callback의 호출시점
우리가 비동기 프로그래밍에서 흔히 하는 실수 중의 하나가 Callback의 시점을 다른 코드와 같이 순차적으로 생각한다는 점입니다. 이는 동기 프로그래밍에 익숙한 개발자에게 자주 나타나는 현상입니다.
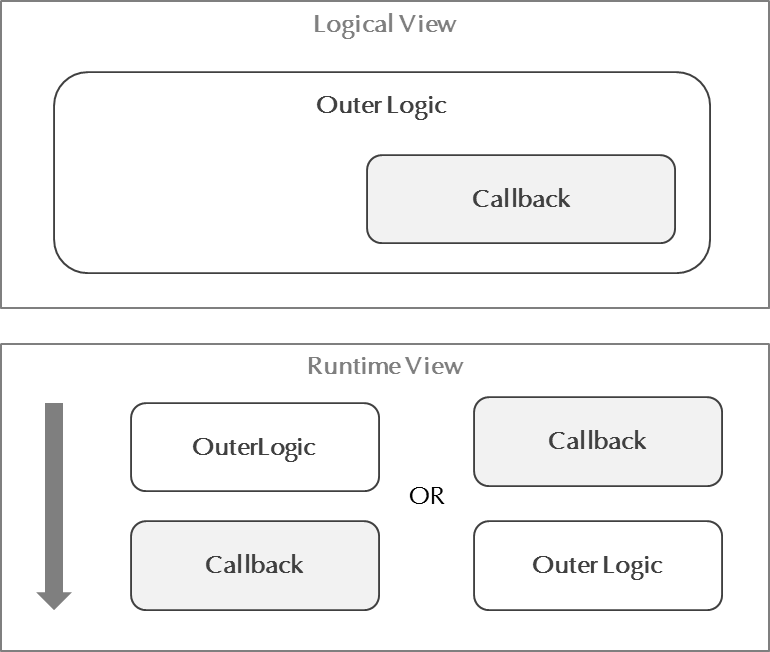
위의 그림과 같이 코드상의 Callback 로직은 가운데에 위치하고 있지만 사실 Runtime에 들어가면 외부 로직과 Callback은 Event Loop에 의해 처리되므로 어느 것이 먼저 실행될 지 알 수 없습니다. 만일 Outer Logic이 중첩된 Callback 형태라면 Outer Logic 이 먼저 실행됩니다.
var fs = require('fs');
function executeCallbacks() {
fs.readdir('.', function (err, filenames) {
var i;
for (i = 0; i < filenames.length; i++) {
fs.stat('./' + filenames[i], function (err, stats){
console.log(i + ':'+stats.isFile());
});
}
});
}
executeCallbacks();
위의 예제에서 fs.readdir() Callback과 fs.stat() Callback이 중첩되었고 내부 Callback은 병렬처리를 위해 여러번 생성되었습니다. 내부 Callback은 외부 Callback의 변수 i에 접근하는데 내부 Callback에서는 모두 같은 값으로 출력합니다. 예를 들어 파일 개수가 5개라면 모두 5, 5, 5,.. 이런식으로 출력됩니다. 왜그럴까요?
이는 외부 Callback과 내부 Callback이 실행시점이 달라서 그렇습니다. 중첩 Callback이므로 외부 Callback이 모두 수행된 후 내부 Callback이 수행됩니다.
var fs = require('fs');
function executeCallbacks() {
fs.readdir('.', function (err, filenames) {
var i;
for (i = 0; i < filenames.length; i++) {
(function(){
var j = i;
fs.stat('./' + filenames[i], function (err, stats){
console.log(j + ':'+stats.isFile());
});
})();
}
});
}
executeCallbacks();
그러면 순차적인 i값을 출력하기 위해서는 외부 Callback 실행시 i값을 어딘가에 저장해야 합니다. 이 예제는 Closure를 생성하여 새로운 Scope를 만들었습니다. 다시말해 즉시실행 함수를 만들었습니다. 그리고 이 Scope의 j 변수에 i값을 저장하고 내부 Callback 실행시 j를 출력하니 비로소 순차적으로 출력되는 것을 확인할 수 있습니다.
비동기 프로그래밍의 이해
지금까지 서버의 동시성을 위한 병렬처리의 개념을 살펴보았고 Node.js가 왜 비동기 방식으로 병렬처리하는지 알아보았습니다. Node 애플리케이션을 개발하려는 개발자는 Node.js의 비동기 방식을 정확히 이해하고 비동기 프로그래밍의 패턴에 익숙해야만 Node 서버의 고성능을 활용할 수 있습니다. 이는 동기 방식에 길들여져 있는 일반 개발자들에게는 힘든 일이 될 수 있습니다.
지금까지 기초적인 수준의 비동기 프로그래밍 패턴을 소개하였습니다. 비동기 프로그래밍은 동기방식보다 까다롭고 복잡합니다. 그러나 이 패턴에 조금만 익숙해 진다면 Node 서버의 고성능이 이를 보상해 줄겁니다.
마지막으로 Node 애플리케이션을 개발해야 하는 첫걸음에 있는 개발자들에게 이 글이 조금이나마 보탬이 되었으면 합니다.
관련글
- Node.js: 비동기 프로그래밍 이해
- Node.js: Hello로 시작하는 Web 애플리케이션