작년에 했던 프로젝트에서 Spring Annotation과 JAXB Annotation을 사용한 경험이 있습니다. Annotation을 이용해서 객체의 속성을 매핑하는데 유용하게 사용했던 기억이 나네요. 하지만 최근에 Annotation에 대해 공부하면서, Java에서 제공하는 Annotation만으로도 효율적으로 사용할 수 있다는 점이 흥미로웠습니다. 그래서 지금부터 제가 공부한 Java Annotation을 효율적으로 활용할 수 있는 한 가지 예를 공유합니다.
1. 어노테이션(@, Annotation)이란?
그 예를 살펴보기에 앞서, 먼저 어노테이션이란 무엇인지부터 정리하겠습니다. 어노테이션(Annotation)은 Java 5부터 등장한 기능입니다. Annotation은 사전을 찾아보면 "주석"이라고 나오지만, 우리가 흔히 사용하는 "//, /**/" 등의 주석과는 차이가 있죠.
어노테이션은 설명 그 이상의 활동을 합니다. 어노테이션이 붙은 코드는 어노테이션의 구현된 정보에 따라 연결되는 방향이 결정됩니다. 따라서 전체 소스코드에서 비즈니스 로직에는 영향을 주지는 않지만 해당 타겟의 연결 방법이나 소스코드의 구조를 변경할 수 있습니다. 쉽게 말해서 "이 속성을 어떤 용도로 사용할까, 이 클래스에게 어떤 역할을 줄까?"를 결정해서 붙여준다고 볼 수 있습니다. 어노테이션은 소스코드에 메타데이터를 삽입하는 것이기 때문에 잘 이용하면 구독성 뿐 아니라 체계적인 소스코드를 구성하는데 도움을 줍니다.
@CanSale
public class Apple {
...
}
<리스트1> 어노테이션 사용의 예
Annotation은 위 <리스트1> 과 같이 @(;AT)을 앞에 붙여서 표현합니다. 이 어노테이션은 자바가 기본적으로 제공하기도 하고(@Deprecated, @Override, @SuppressWarnings), 개발자가 직접 정의해서 사용할 수도 있습니다. 개발자는 어노테이션을 붙일 타겟과 유지시기 등을 설정하여 자신이 원하는 용도로 활용 가능합니다. 이 기능을 잘 활용한다면, 비즈니스 로직과는 별로도 시스템 설정과 관련된 부가적인 사항들은 @에게 위임하고 개발자는 비즈니스 로직 구현에 집중할 수 있습니다. 따라서 어노테이션을 통해 우리는 AOP(Aspect Oriented Programing; 관심지향프로그래밍)을 편리하게 구성할 수 있습니다. 어노테이션은 컴파일시기에 처리될 수도 있고 자바의 리플렉션을 거쳐서 런타임에 처리될 수도 있습니다. 리플렉션은 실행중인 자바 클래스의 정보를 볼 수 있게 하고, 그 클래스의 구성 정보로 기능을 수행할 수 있도록 합니다. 따라서 자바는 리플렉션 기능이 있기 때문에 어노테이션을 더욱 효율적으로 활용할 수 있습니다.
2. Custom Annotation의 사용
어노테이션을 직접 정의하고 사용하는 방법에 대한 이해를 돕기 위해 아래 그림을 통해 설명합니다.
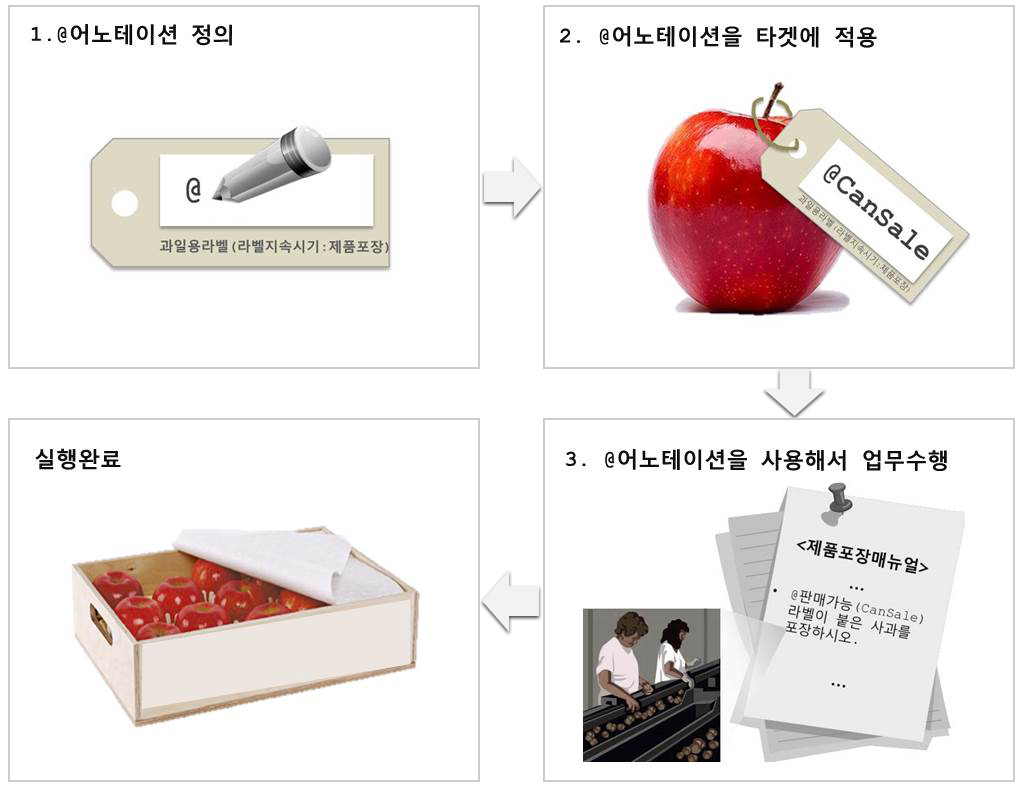
어노테이션은 소스코드에 붙이는 하나의 라벨이라고 생각하면 이해가 쉽습니다. 위 그림은 커스텀 어노테이션의 사용과 실행 절차를 사과가 포장되는 과정에 비유하여 설명하고 있습니다. 판매가능한 사과에는 판매가능(@CanSale)라벨지를 달아서 포장과정시 이를 판별하여 제품을 포장한다고 가정해볼게요. 그렇다면 먼저, 타겟에 적합한 라벨지를 만들어야 합니다. 라벨에는 이 라벨을 붙일 대상을 명시하고, 라벨은 언제까지만 타겟에 부착할 것인지 등을 적습니다. 그리고 라벨에 이름을 적으면 라벨이 만들어집니다. 사과의 상태에 따라 판매가능 라벨을 부착합니다. 즉, 싱싱한 사과라는 타겟에 판매가능이라는 어노테이션을 부착한 것입니다. 그럼 제품포장 과정에서는 이 라벨을 보고 판별하여 제품을 포장할 것입니다. 이렇게 제품 포장 기능이 실행되어집니다.
이와같이 어노테이션을 직접 정의해서 사용하기 위해서는 먼저 어노테이션을 정의한 후, 원하는 타겟에 적용합니다. 그 후 어노테이션이 붙은 타겟을 어떻게 사용할 지 기능을 구현하면, 해당 기능이 실행될 때 타겟에 붙은 어노테이션에 따라서 타겟의 경로가 결정될 것입니다. 커스텀 어노테이션의 구현에 대해서는 3. 효율적인 Annotation 사용의 예에서 살펴봅니다.
3. 효율적인 Annotation 사용의 예
이제부터는 효율적으로 어노테이션을 사용한 예를 살펴 봅니다. 문제상황은 다양한 도메인 객체를 단순한 map 저장소에 저장하기 위해서는, 서로 다른 객체에서 정의되어 있는 key를 어떻게 식별해야 할까? 입니다.
그 방법으로는 '객체마다 방법을 설정하기', '인터페이스 상속으로 객체의 형태를 통일시키기', '어노테이션을 이용해서 key설정하기' 이렇게 세가지가 있었습니다. 이 세가지를 아래에서 자세히 들여다 봅니다.
① 도메인 객체마다 그에 맞는 방법으로 저장
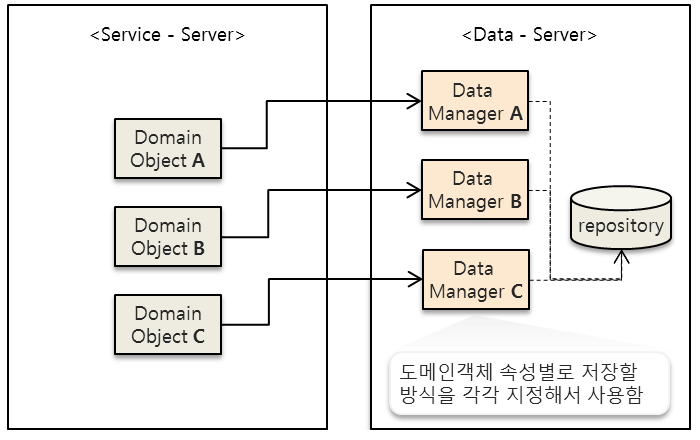
가장 원초적인 방법은 서로 다른 도메인 객체에 맞는 처리 방법을 지정해 주는 것입니다. 하지만 이 방법은 도메인 객체가 늘어날 때마다 데이터 관리 방법을 추가 지정해줘야하는 번거로움이 있습니다. 또한 Data-Server에서 Service-Server의 도메인객체의 속성을 알고 있어야 한다는 점에서 좋지 않은 설계입니다.
② 특정 인터페이스를 상속한 도메인 객체들을 일관된 방법으로 저장
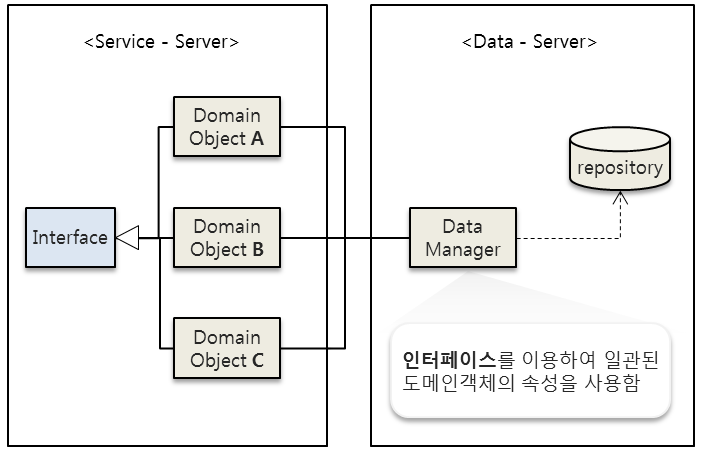
두번째 방법은 인터페이스 상속을 이용한 방법입니다. Service-Server에 있는 모든 도메인 객체가 데이터관리를 위한 틀로서 작용할 수 있는 특정 인터페이스를 상속받도록 하는 것입니다. 이렇게 되면 Data-Server에서는 일관된 도메인객체의 속성을 사용하기 때문에 도메인 객체가 여러 개이더라도 데이터 서버 구현은 한 번만 정의해서 데이터를 관리할 수 있습니다.
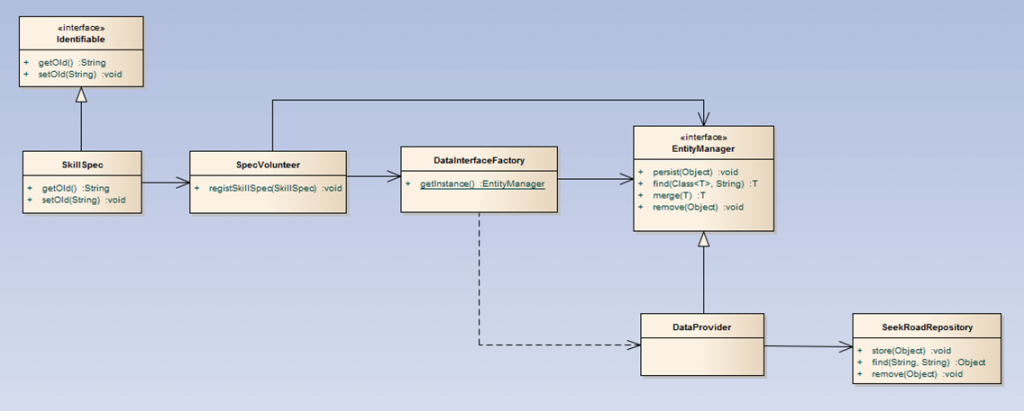
<UML1>은 객체 SkillSpec을 저장, 조회, 삭제하는 시스템의 Class Diagram입니다. SkillSpec이 상속받고 있는 Identifiable 인터페이스에는 getOId, setOId 메소드가 있습니다. 따라서 Data-Server에서는 다른 것을 신경쓰지 않고 oId 속성을 key로 식별하면 됩니다. 또한 새로운 객체를 저장하거나 조회할 때에도 Identifiable을 상속받으면 Data-Server를 수정없이 진행할 수 있습니다.
public interface Identifiable {
//
public String getOId();
public void setOId(String oId);
}
<리스트2> 객체의 key를 통일시키기위한 Identifiable 인터페이스
<리스트2>는 <UML1>에 있는 Identifiable의 구현소스입니다. 이렇게 정의된 Identifiable 인터페이스는 아래와 같이 활용할 수 있습니다.
public class SeekRoadRepositoryWithoutAnno {
//
private static Map<String,Identifiable> objectMap = new HashMap<String,Identifiable>();
private static SeekRoadRepositoryWithoutAnno repository;
// (생략)
public void store(Identifiable identifiableEntity) {
//
String className = identifiableEntity.getClass().getName();
if (sequenceMap == null) {
sequenceMap = new HashMap<String,AtomicInteger>();
sequenceMap.put(className, new AtomicInteger(0));
}
AtomicInteger currentSequence = sequenceMap.get(className);
String key = className+ "." + Integer.toString(currentSequence.incrementAndGet());
identifiableEntity.setOId(key);
objectMap.put(key, identifiableEntity);
}
}
<리스트3> 인터페이스를 통한 데이터 저장 메소드
<리스트3>은 객체를 objectMap에 저장하는 store메소드입니다. 소스코드에서 보면 objectMap<String, Identifiable>로 선언하였습니다. 즉, 어떤 객체라도 그 객체는 Identifiable 인터페이스를 상속받고 있기 때문에 primary Key를 식별 가능하며, 저장하기 전 클래스 이름과 시퀀스넘버를 더하여 key로 설정하였습니다. 그러므로 서로 다른 객체가 수없이 저장되더라도 유니크한 키를 지정받을 수 있습니다. 또한 객체에서 key로 지정한 속성이 다르더라도 Identifiable의 getOId, setOId의 메소드를 오버라이딩하여 사용하기 때문에 인터페이스 단계에서 가져다 쓸 수 있습니다. 방법①을 사용했다면 store메소드를 storeSpecSkill, storeRoleSkill 등 객체가 늘어날 때 마다 그에 맞는 방법으로 저장을 했어야 했지만, 인터페이스 상속을 통해 이런 불편함을 줄일 수 있었습니다.
하지만 ②의 경우에는 몇 가지의 문제점이 있습니다. 첫째, 도메인 객체가 데이터 저장을 위해 불필요하게 인터페이스를 상속받아야 합니다. 도메인 객체는 업무상으로도 여러 상속관계를 가질 수 있습니다. 사용자 객체를 상속받는 회원과 관리자 객체처럼 말입니다. 둘째, 방법②는 객체의 충돌이 일어날 가능성이 있습니다. 도메인과 서비스단을 모두 개발한 후 데이터 관리를 위해 인터페이스를 상속받도록 리팩토링한다고 했을 때, 인터페이스는 기존의 객체들과 속성이 충돌이 되어서는 안되기 때문에 이를 고려해야 합니다. 따라서, 방법②는 개발자 자신이 구현하려는 비즈니스와 관련없이 데이터 저장방법을 위해서 소스코드에 상속을 추가함으로써 더 이상 비즈니스로직에만 집중할 수 없게 된다는 약점이 있습니다.
③ @Annotation을 이용해서 저장
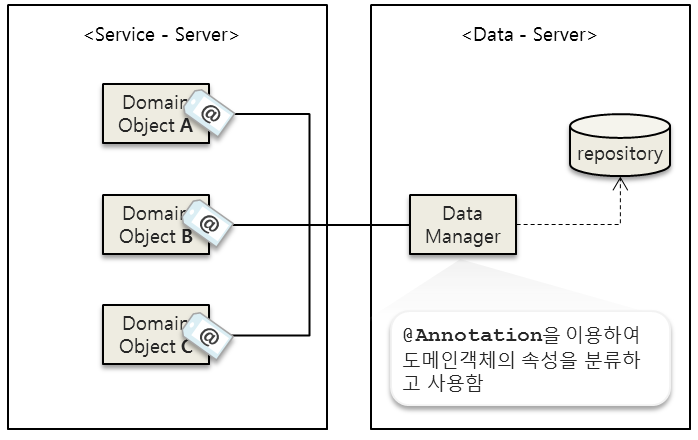
반면, 방법③은 위에 쓴 방법②의 불편함을 해소한 방법입니다. 바로 어노테이션을 이용해서 도메인객체를 처리하는 방법입니다. 서로 다른 도메인 객체이더라도 같은 어노테이션이 붙어있으면 똑같은 경로로 나가도록 구현할 수 있기 때문에 인터페이스를 상속받지 않더라도 통합된 방법으로 데이터관리를 할 수 있습니다.
어노테이션 정의
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
public @interface ObjectId {
}
<리스트4>어노테이션 정의
위 <리스트4>는 어노테이션의 정의 방법입니다. @Target은 말 그대로 어노테이션의 타겟을 지정하는 것입니다. 따라서 해당 어노테이션을 Feild에 붙일 것이면 FIELD, Class나 Enum 등의 타입에 붙일 때는 TYPE 등으로 어떤 대상을 위한 어노테이션인지를 설정합니다. 그 아래에 있는 Retention은 어노테이션의 지속기간입니다. 개발자는 해당 어노테이션을 소스코드에서 단순 주석으로 사용할 지, 컴파일시기까지 유지할지, 런타임까지 유지할 것인지를 결정할 수 있습니다. 자세한 설명은 http://kang594.blog.me/39704853을 참고하시면 좋을 것 같습니다. 어노테이션 공부를 하는데 큰 도움이 되었던 블로그입니다.
이렇게 Field에 적용할 수 있고 Runtime까지 유지되는 ObjectId 어노테이션을 정의합니다. 이 ObjectId는 각 객체의 key가 될 속성에 붙여서 해당 객체의 ID 필드를 식별하는데 사용합니다.
타겟에 어노테이션 적용
public class SkillSpec {
//
@ObjectId
private String oId;
private String name;
private SkillCategory skillCategory;
...
}
<리스트5>어노테이션 적용
<리스트5>는 어노테이션을 적용한 소스 코드입니다. oId 필드에 ObjectId 어노테이션을 붙이므로서 Data-Server에서는 편리하게 이 객체의 key를 식별할수 있습니다.
어노테이션을 이용한 기능 구현
public class ObjectIdAnnotator {
...
public static String getObjectIdValue(Object entity) {
//
Class<? extends Object> clazz = entity.getClass();
for (Field field : clazz.getDeclaredFields()) {
if (field.getAnnotation(ObjectId.class) != null) {
field.setAccessible(true);
Object value = field.get(entity);
if (value == null) {
return null;
} else {
return value.toString();
}
}
}
throw new RuntimeException("No annotated id field.");
}
}
<리스트6>어노테이션을 이용한 기능 구현
위 <리스트6>에 보면 어노테이션을 식별해서 구현한 메소드를 볼 수 있습니다. ObjectIdAnnotator는 <리스트4>에서 정의한 ObjectId 어노테이션을 식별해서 이에 해당하는 필드에 대한 처리를 구현하였습니다. Java 리플렉션을 통해서 우리는 필드 정보를 얻어서 해당 필드에 붙어있는 어노테이션의 정보까지 사용할 수 있기 때문에 편리하게 구현이 가능합니다.
어노테이션을 사용한 객체 저장 메소드
public class SeekRoadRepository {
//
private static Map<String,StoredObject> objectMap = new HashMap<String,StoredObject>();
private static SeekRoadRepository repository;
// ...(생략)
public void store(Object entity) {
//
StoredObject object = new StoredObject(entity);
objectMap.put(object.getId(), object);
}
}
<리스트7-1>어노테이션을 사용한 객체의 저장 메소드
public class StoredObject {
//
private static Map<String,AtomicInteger> sequenceMap;
private String oId;
private String className;
private Object object;
//... (생략)
//--------------------------------------------------------------------------
public StoredObject(Object entity) {
//
this.className = entity.getClass().getName();
this.oId = nextSequence(this.className);
if (getObjectId(entity) == null) {
ObjectIdAnnotator.setObjectIdField(entity, oId);
}
this.object = entity;
}
//... (생략)
}
<리스트7-2>어노테이션을 이용한 데이터 관리에서 대상이 되는 객체 클래스
<리스트7>은 위 방법②에서 사용한 <리스트3>의 저장메소드와 비교해서 볼 수 있습니다. 대상 객체클래스를 따로 분리한 것을 제외하고는 전체적인 흐름은 같습니다. 그러나 <리스트 7-2>의 StoredObject 클래스의 생성자를 보면 저장할 객체를 생성할 때 <리스트 6>의 ObjectAnnotator에 구현되어 있는 ObjectId가 붙은 Field값을 설정하는 로직이 있습니다. 클래스이름과 순번으로 맵에 저장할 객체들에게 모두 유일한 시퀀스넘버를 제공합니다. 이렇게 유일한 값을 구해서 어떤 객체라도 상관없이 ObjectId 어노테이션이 붙어있는 속성에 키 값을 셋팅하기 때문에 해당 Map에 저장되는 모든 객체는 유일한 Key값을 어노테이션 ObjectId의 타겟인 속성에 저장합니다. 따라서 형태가 다른 객체에 대해 각각 방법을 지정하지 않더라도, 이 방법을 사용하면 서로 키가 충돌이 나거나 중복된 키로 인해 기존 객체가 덮어씌워지는 상황이 일어나지 않습니다.
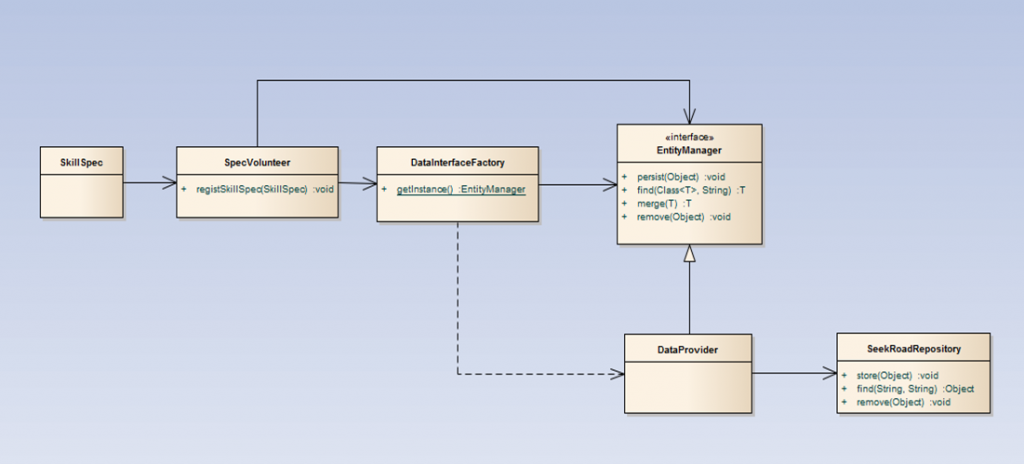
<UML2>는 여태까지 살펴 본 데이터 관리 방법 ③에 대한 UML입니다. Annotation을 UML에 표현하는 방법에는 여러가지가 있고 또 여러 제안이 나오고 있습니다. 때문에 표준으로 추상화해야되는 UML만을 보고 어노테이션의 관계까지 파악하기에는 어려움이 있습니다. 그러나 모델링은 소스코드보다 추상화레벨이 높습니다. 따라서 소스코드와 모델링은 완전히 일치시키기에는 여러 어려움이 따를 것입니다. 지금까지 객체 모델링을 통한 방법 ②보다 Java언어 매커니즘인 어노테이션을 이용한 방법③이 더욱 효율적일 수 있다는 것을 살펴보았기 때문입니다. 이 스터디를 통해, 언어를 모델이 따라오지 못한다면 모델에 얽메이지 않고 시스템을 설계하는 것이 더욱 효율적이라는 것을 느낄 수 있었습니다.
참고 논문 및 사이트
- Vasian Cepa, Sven Kloppenburg, "Representing Explicit Attributes in UML"
- 넥스트리블로그, 김현오 선임, 객체구조탐색의 대안 (http://www.nextree.co.kr/p3643/)
- Jenkov.com (http://tutorials.jenkov.com/java-reflection/annotations.html)
- "강이"의 JAVA강좌 (http://alecture.blogspot.kr/2011/06/annotation.htm)
- vogella.com (http://www.vogella.com/tutorials/JavaAnnotations/article.html#javaannotations)
- The Wheel Of Developer (http://kang594.blog.me/39704853)